

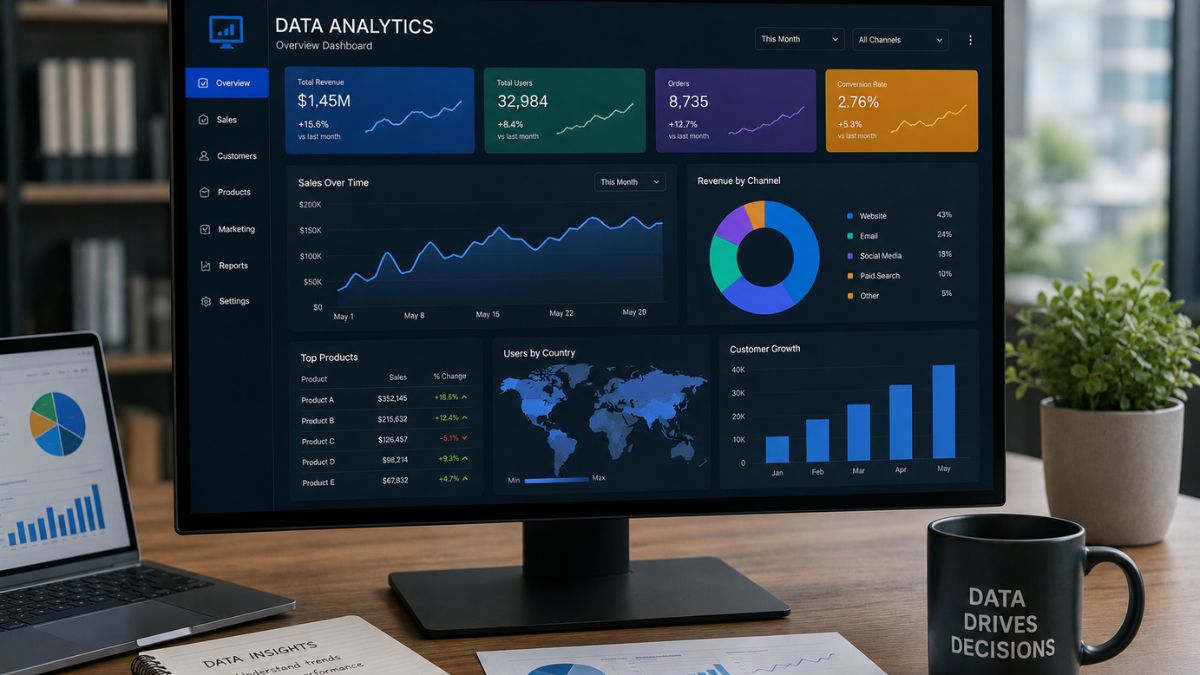


The data analytics market in 2026 is defined by two converging forces: the maturation of the modern data stack into a relatively stable architectural consensus, and the rapid disruption of the business intelligence layer by AI. On the infrastructure side, the combination of Snowflake or Databricks for compute, Fivetran or Airbyte for ingestion, dbt for transformation and a BI tool on top has become sufficiently established that industry practitioners now describe it as a settled default rather than an architectural choice. The recently announced merger between Fivetran and dbt Labs, creating what both companies call an open data infrastructure alternative to single-vendor suites, signals that even the tooling ecosystem itself is beginning to consolidate around these patterns.
At the business intelligence layer, the disruption is more radical. Every major platform, from Tableau to Power BI to Qlik to Looker, has shipped agentic AI capabilities in the past eighteen months, moving from dashboards that answer questions to agents that investigate data autonomously. Tableau Next introduced Data Pro, Concierge and Inspector agents alongside Tableau Semantics; Power BI embedded Copilot across DAX generation, natural language reporting and Fabric integration; ThoughtSpot shipped SpotterViz for instant AI-generated dashboards; and Sigma Computing launched autonomous agents capable of executing writes, triggering webhooks and interfacing with external systems directly from within an analysis. A newer generation of platforms, including Tellius, DataGPT and Julius AI, has been built from the ground up around AI-first investigation rather than retrofitting intelligence onto traditional dashboard architectures. Meanwhile the Open Semantic Interchange standard, launched by Snowflake in late 2025 and now backed by Databricks, dbt Labs, ThoughtSpot, Sigma, Google and AWS, is establishing a shared layer through which a metric defined once can be consumed consistently by any BI tool, AI agent or analytics platform in the stack.
This guide covers 59 tools across nine categories that together span the complete data analytics landscape: enterprise BI and dashboards; AI-native and augmented analytics; cloud data warehouses and lakehouse platforms; data integration, transformation and orchestration; data governance, cataloging and observability; product and digital experience analytics; web, marketing and revenue analytics; data science, notebooks and data preparation; and embedded and open-source analytics. Each category is relevant to a different team and problem, and most organizations of meaningful scale need tools from several of these categories simultaneously rather than a single platform that claims to solve everything.
Enterprise BI & Dashboards
These platforms are the backbone of organizational reporting, transforming raw data into interactive dashboards, governed reports and self-service visualizations for business users. Their key differentiator ranges from Microsoft ecosystem depth to pixel-perfect visual storytelling to associative exploration engines that let users follow data relationships freely. Buyers span every department in mid-to-large organizations that need a single, consistent view of performance metrics across teams and geographies.
Microsoft Power BI
Microsoft Power BI is the market leader in business intelligence by adoption, deployed across more than 350,000 organizations globally and holding roughly 20 percent of the BI market share as of 2026. Its defining advantage is deep, native integration with the Microsoft 365 and Azure ecosystem: Power BI reports surface inside Teams, Excel connects bidirectionally to live semantic models, and Fabric unifies Power BI with data engineering and data science workloads under one governed platform. The embedded Copilot engine, available on Premium and Fabric capacity, automates DAX query generation for analysts and handles natural language reporting requests for business staff who would otherwise need to file data team tickets. Power BI Pro is priced at $14 per user per month, making it the most cost-effective enterprise BI platform on the market, though organizations needing AI features, large-scale distribution or paginated reports must upgrade to Premium or Fabric capacity, where costs scale considerably. For organizations already standardized on Microsoft infrastructure, Power BI is rarely displaced; for organizations outside the Microsoft ecosystem, its depth of Azure dependency can be a liability rather than an advantage.
Features: native Microsoft 365, Teams, Excel and Azure integration, Copilot natural language report generation, DAX query automation, Fabric unified data and BI platform, real-time streaming dashboards, row-level security and role-based access control, Power Query data transformation, paginated reports for pixel-perfect output, and the lowest per-user licensing cost among enterprise BI platforms.
Best for: organizations already standardized on Microsoft infrastructure, including Azure, Teams, Excel and SharePoint, that want cost-effective, governed self-service reporting tightly woven into the productivity tools their staff already use daily.
Tableau
Tableau remains the gold standard for sophisticated data visualization and interactive visual storytelling, with a drag-and-drop VizQL interface that lets analysts build dashboards of a depth and aesthetic quality that competing platforms consistently struggle to match. Now sitting inside Salesforce’s product portfolio, Tableau has evolved substantially beyond its visualization roots with the arrival of Tableau Next, which adds three AI agents including a Data Pro, a Concierge and an Inspector, alongside Tableau Pulse, a proactive metric layer that pushes personalized anomaly summaries directly to stakeholders’ workflows in Slack and email without requiring them to open a dashboard. Tableau Semantics, a new centralized semantic layer, addresses one of the platform’s long-standing weaknesses by enforcing consistent metric definitions across all dashboards and AI-generated answers. Pricing runs from $15 per month for Viewer access to $115 per month for Enterprise Creator, with total cost of ownership typically higher than Power BI when training and implementation are included. For organizations with dedicated analytics teams that prioritize visual depth, exploratory analysis across large datasets and the Salesforce ecosystem, Tableau is frequently the platform that competitors are measured against.
Features: VizQL drag-and-drop visual analytics with industry-leading visualization grammar, Tableau Next agentic AI with Data Pro, Concierge and Inspector agents, Tableau Pulse proactive metric summaries and anomaly alerts, Tableau Semantics centralized semantic layer, Tableau Prep data wrangling, broad data source connectivity, cloud and on-premises deployment options, Salesforce ecosystem integration, and mobile-optimized dashboard access.
Best for: analytics teams and organizations prioritizing visual depth, exploratory data storytelling and Salesforce ecosystem integration, where the quality of visualization and the ability to build bespoke, highly interactive dashboards justifies a higher per-user cost than alternatives.
Looker
Looker takes a fundamentally different approach to BI from Tableau or Power BI, centering its architecture on LookML, a centralized semantic modeling language that forces every department to reference the same definitions for core KPIs rather than building their own calculations inside individual dashboards. This governance-first design makes Looker the strongest choice when metric consistency across a large organization is the primary requirement, particularly in environments with strong data engineering teams that want to version-control business logic like code. As a Google Cloud product, Looker integrates natively with BigQuery and benefits from Gemini-powered natural language capabilities that let business users query governed data models in plain English. Its embedded analytics capability is also among the strongest in the category, making it a common choice for product teams building analytics into internal tools or customer-facing applications. The tradeoff is a slower, more technically demanding implementation relative to Power BI or Tableau: LookML development is time-intensive initially, and the platform assumes the presence of at least one dedicated analytics engineer who understands data modeling.
Features: LookML centralized semantic modeling language enforcing consistent metric definitions, Google Cloud and BigQuery native integration, Gemini natural language querying on governed data models, strong embedded analytics for internal and customer-facing applications, Git version control for semantic model changes, real-time warehouse queries without data extraction, row-level security and fine-grained access control, API-first architecture for custom integrations, and a developer-focused workflow favored by analytics engineering teams.
Best for: data-engineering-led organizations, particularly those on Google Cloud or BigQuery, that prioritize metric consistency across departments and want business logic version-controlled in code rather than scattered across individual dashboard calculations.
Qlik Sense
Qlik Sense is built around its Associative Query Engine, a technically distinctive approach that allows users to explore multi-layered data relationships freely without being constrained by the predefined hierarchies that standard SQL-based query tools impose. When a user selects a value in Qlik, the engine highlights related and unrelated values across every connected table simultaneously, surfacing hidden relationships that a traditional query would filter out entirely, which makes it particularly powerful for discovering unexpected correlations in complex operational datasets. Qlik Cloud Analytics has added Qlik Answers, a generative AI knowledge assistant that queries unstructured content including PDFs, SharePoint and Confluence documents alongside structured warehouse data, and Qlik AutoML for no-code machine learning inside the analytics environment. The platform supports both cloud and on-premises deployment, which matters for regulated industries with data residency requirements. Pricing starts at around $200 per month for ten users on Qlik Business, with Enterprise plans requiring a custom quote, and the associative model requires deliberate data modeling upfront to realize its full value.
Features: Associative Query Engine for free-form data relationship exploration, Qlik Answers generative AI assistant for unstructured and structured data, Qlik AutoML for no-code machine learning, AI-powered Insight Advisor recommendations, cloud and on-premises deployment flexibility, interactive data storytelling with visualization narratives, self-service analytics without predefined query paths, strong hybrid cloud support for regulated industries, and a dedicated learning platform for structured analytics training.
Best for: organizations needing to discover unexpected relationships across complex, multi-source datasets where traditional linear query structures prevent analysts from following the data wherever it leads, and for regulated industries requiring on-premises or hybrid deployment.
Domo
Domo positions itself as an all-in-one cloud BI ecosystem rather than a pure visualization tool, combining more than 1,000 pre-built data connectors, an ETL and data preparation layer called Magic Transform, dashboard and visualization capabilities and an AI layer into one managed platform that minimizes the infrastructure setup burden for mid-market teams. This plug-and-play approach is Domo’s primary differentiator: rather than assembling a separate ingestion tool, a transformation layer, a semantic model and a visualization platform, a team on Domo can get from raw data to governed dashboards within a single vendor relationship. The platform’s Domo.AI module adds natural language querying, automated insight generation and AI app building on top of the BI layer, and its mobile-first design makes executive dashboards accessible on any device. Average annual contract value is reported around $134,000, positioning Domo firmly at mid-market and enterprise buyers rather than small teams, and its cost-per-feature value is frequently questioned relative to assembling a best-of-breed modern data stack with individual tools.
Features: 1,000-plus pre-built data connectors spanning SaaS, databases and files, Magic Transform AI-powered data preparation and ETL, integrated BI, dashboards and data storytelling, Domo.AI for natural language querying and automated insights, AI app building on governed data, mobile-first executive dashboards with real-time alerts, embedded analytics capability, a marketplace of pre-built app templates, and an all-in-one architecture reducing multi-vendor complexity.
Best for: mid-market organizations that want a single vendor covering ingestion, transformation, visualization and AI without the operational overhead of assembling and maintaining a best-of-breed stack, and where minimizing infrastructure complexity matters more than maximizing flexibility.
Sisense
Sisense is built primarily around embedded analytics, the discipline of delivering analytics directly inside customer-facing applications and internal tools rather than routing users to a separate BI portal. SaaS companies and product teams choose Sisense when the goal is to give their own end users analytics experiences that feel native to the product rather than bolted on, which requires a developer-first architecture, strong white-labeling and a flexible component model rather than the self-service-analyst-first designs of platforms like Tableau or Power BI. Sisense’s in-chip analytics technology historically allowed it to query large datasets in memory with low latency, and its cloud platform has evolved to support multi-cloud deployments across AWS, Azure and Google Cloud. Pricing starts around $10,000 per year for basic deployments and scales to custom enterprise contracts for high-volume embedded use cases. For internal analytics needs without an embedded product angle, Sisense’s developer-first orientation can feel over-engineered relative to more business-user-friendly alternatives.
Features: developer-first embedded analytics architecture for customer-facing and internal applications, white-labeling and component-level customization, in-chip analytics for low-latency large-dataset queries, multi-cloud deployment across AWS, Azure and Google Cloud, a flexible API for custom integration into product workflows, AI-generated insights and anomaly detection, a drag-and-drop dashboard builder for non-developer users alongside developer APIs, and strong SaaS and ISV customer base across analytics-as-a-product use cases.
Best for: SaaS companies and product teams building analytics directly into their own products or internal applications for end users, where the analytics must feel native to the product experience rather than directing users to a separate reporting portal.
Metabase
Metabase is the most widely adopted open-source BI tool in the market, valued for a combination of fast time-to-value, a genuinely accessible interface for non-technical business users and transparent architecture that gives engineering teams full control over where data lives and how the tool is deployed. Its self-hosted open-source edition is free, making it one of the few no-cost entry points into proper BI tooling, while Metabase Cloud and the Pro plan add collaboration, permissions and embedding features at a fraction of the cost of enterprise alternatives. The platform intentionally trades governance depth and semantic modeling sophistication for accessibility and simplicity: business users can answer straightforward data questions through a visual query builder without writing SQL, while analysts can drop into SQL mode for more complex work. Organizations that outgrow Metabase typically cite the need for stronger governance, formal semantic modeling or more complex multi-step analytical workflows as the reasons for migrating to Looker, Power BI or a more enterprise-grade platform.
Features: free self-hosted open-source edition with full SQL and visual query capability, a visual question builder requiring no SQL knowledge, Metabase Cloud for managed hosting, automated pulse reports on a schedule, simple embedding for customer-facing analytics, a clean and accessible interface designed for non-technical business users, broad connector support across common databases and warehouses, role-based permissions and row-level security on paid plans, and the fastest time-to-value of any BI platform at any team size.
Best for: startups, small-to-mid-sized teams and engineering-led organizations that want fast, accessible BI with minimal setup cost, particularly those comfortable with self-hosting and willing to trade some governance depth for simplicity and price.
Google Looker Studio
Google Looker Studio is Google’s free, browser-based reporting and visualization tool, distinct from the enterprise Looker platform despite sharing a name, offering drag-and-drop dashboard building with native connectors to Google Analytics, Google Ads, BigQuery, Google Sheets and the broader Google ecosystem. Its zero-cost positioning makes it the default starting point for teams already using Google’s marketing and analytics products, particularly for marketing and campaign reporting that combines Google Ads performance data with website traffic from GA4 in a single shareable dashboard. Looker Studio Pro adds collaboration, workspace management and enterprise-grade access controls for teams that need more than the free tier offers, at modest pricing. The platform’s limitations become apparent at scale: complex data transformations require building them in BigQuery first, semantic modeling is absent, and the free version lacks the governance controls that larger organizations require. For teams already in the Google ecosystem needing a fast, free reporting surface, Looker Studio is typically the easiest first step before evaluating whether a dedicated BI platform is justified.
Features: completely free to use with no user-based licensing, native connectors to Google Analytics, Google Ads, BigQuery and Google Sheets, drag-and-drop report and dashboard builder, real-time data from connected Google sources, shareable and embeddable reports, a community connector library for non-Google data sources, Looker Studio Pro for workspace management and team collaboration, and zero infrastructure setup required for Google-ecosystem data.
Best for: marketing and digital teams already using Google Analytics, Google Ads and Google Sheets who need a free, fast reporting surface to combine those sources into shareable dashboards without purchasing a dedicated BI platform.
Zoho Analytics
Zoho Analytics delivers a self-service BI platform specifically positioned for small and mid-sized businesses that need more analytical power than a spreadsheet but cannot justify the licensing cost of Tableau, Looker or Power BI. Its AI assistant Zia answers plain-English questions about connected data and surfaces automatic insights without requiring a data analyst, and its broad library of pre-built connectors covers Zoho’s own CRM, finance and HR applications alongside common third-party business tools. Zoho Analytics is particularly strong when a business is already using Zoho CRM, Zoho Books or other Zoho suite products, since native integration between those applications and the analytics layer is seamless by design. Pricing starts from free for up to two users and two data sources, with paid plans beginning at around $30 per month, making it one of the most accessible paid BI tools for budget-conscious small businesses. The tradeoff is limited depth in semantic modeling, data governance and advanced analytics relative to enterprise platforms, and organizations with complex multi-source data pipelines will find it constraining.
Features: Zia AI assistant for natural language data questions, automatic insight generation and anomaly detection, a broad pre-built connector library including Zoho suite integration, scheduled data syncing and data blending across sources, collaborative commenting and sharing, a free tier for small teams, competitive SMB pricing, a drag-and-drop report builder, KPI widgets and custom dashboards, and embedded analytics for Zoho ecosystem products.
Best for: small and mid-sized businesses, particularly those already using the Zoho product suite, that need BI and AI-powered insights at an accessible price point without the implementation complexity or licensing cost of enterprise platforms.
Amazon QuickSight
Amazon QuickSight is AWS’s cloud-native, serverless BI service, designed to integrate naturally with the broader AWS data ecosystem including Redshift, S3, Athena, RDS and the growing range of AWS analytics services. Its session-based pricing model, starting at $0.30 per session for readers, is structurally different from the per-user seat models of most competitors, which can result in significantly lower total cost of ownership for organizations with large numbers of occasional dashboard consumers who log in infrequently. QuickSight’s SPICE in-memory engine pre-aggregates data for fast query performance on large datasets, and the platform has added Q, its natural language querying capability, alongside more recent generative BI features that auto-generate narrative summaries of dashboard data. For organizations outside the AWS ecosystem, QuickSight’s relatively limited visualization sophistication compared with Tableau and its AWS-centric connector library make it a weaker choice than more ecosystem-neutral alternatives.
Features: session-based pricing model starting at $0.30 per reader session for cost efficiency at scale, native integration with the full AWS data ecosystem including Redshift, S3, Athena and RDS, SPICE in-memory engine for fast pre-aggregated queries, QuickSight Q natural language querying, generative BI narrative summaries, serverless architecture with automatic scaling, ML-powered anomaly detection and forecasting, embedded analytics with pay-per-session economics, and a broad connector library biased toward AWS services.
Best for: AWS-native organizations with large numbers of occasional dashboard consumers who would face high per-seat licensing costs on traditional BI platforms, where QuickSight’s session-based pricing model and native AWS integration deliver meaningful total cost of ownership advantages.
Apache Superset
Apache Superset is a widely used open-source data exploration and visualization platform, originally created at Airbnb and now an Apache Software Foundation project with active community contributions from dozens of major technology companies. Its SQL Lab editor gives analysts a full SQL IDE with query history, schema browsing and result visualization in a single browser tab, while the dashboard layer supports a wide range of chart types built on Echarts and D3. Superset connects directly to virtually every major database and data warehouse via SQLAlchemy, making it database-agnostic in a way that proprietary tools are not. As an open-source project, Superset carries a licensing cost of zero, but production deployments require engineering effort to set up, secure and maintain, and the configuration complexity is meaningfully higher than cloud-managed alternatives. Preset, the commercial company backed by the Superset creator, offers a managed Superset-as-a-service for teams that want the open-source flexibility without the infrastructure burden.
Features: free open-source Apache license with no per-user cost, a full SQL Lab IDE with query history, schema browsing and result caching, a wide chart library built on Echarts and D3, SQLAlchemy-based connectivity to virtually every database and data warehouse, a drag-and-drop dashboard builder, row-level security and role-based access control, an active community with contributions from Airbnb, Lyft, Twitter and others, and Preset managed cloud hosting for teams avoiding self-hosted infrastructure.
Best for: engineering-led organizations and technical data teams that want a capable, database-agnostic, zero-license-cost BI and SQL exploration platform and have the engineering resources to deploy and maintain it, or teams using Preset’s managed offering.
Mode Analytics
Mode Analytics combines a SQL query editor, a Python and R notebook environment, and a dashboard layer in a single platform designed specifically for data analysts who think in queries first rather than drag-and-drop interactions first. This makes Mode distinctly analyst-native rather than business-user-native: analysts write SQL to pull and shape data, optionally extend their analysis with Python or R, and then surface results in a shareable report or dashboard that business stakeholders can consume without needing to understand the underlying code. Mode’s Helix in-memory store caches query results for fast dashboard performance, and its report-sharing model is built around collaboration between analysts and their business partners. ThoughtSpot acquired Mode in 2023, positioning Mode as the analyst-facing layer in ThoughtSpot’s broader analytics ecosystem. For data teams that want a unified environment for ad-hoc SQL analysis, notebook-style exploration and governed reporting without switching between multiple tools, Mode fills a gap that neither a pure BI platform nor a pure notebook environment covers as cleanly.
Features: unified SQL editor, Python and R notebook, and dashboard layer in one platform, Helix in-memory query result caching for fast dashboard loading, report sharing with version history and collaborative commenting, a chart builder surfacing SQL query results as visualizations, dbt model integration for working with transformed data, a report template library for common analytical patterns, ThoughtSpot integration following the 2023 acquisition, and a workflow optimized for analyst-to-business-stakeholder collaboration.
Best for: data analyst teams that write SQL as their primary analytical tool and want a single environment covering ad-hoc query exploration, Python and R analysis and shareable dashboard reporting without switching between a separate SQL editor, notebook and BI platform.
AI-Native & Augmented Analytics
This category covers platforms built from the ground up around natural language querying, agentic analysis and automated root-cause investigation, where the AI does substantive analytical work rather than simply generating a chart from a typed question. Their differentiator is the depth of interpretation sitting beneath the natural language interface — from search-based warehouse querying to multi-step agentic investigations that explain why a metric changed at a granular level. Buyers are organizations whose business users consistently queue up questions for data analysts and want AI to handle a meaningful share of that investigative work autonomously.
ThoughtSpot
ThoughtSpot pioneered search-based analytics and remains the strongest platform for letting non-technical business users query governed cloud warehouse data in plain conversational English, producing visualizations and insights without analyst involvement. Its Spotter AI Analyst, the third generation of its conversational analytics engine, goes significantly beyond simple text-to-SQL translation: users ask complex multi-part questions and Spotter autonomously parses the warehouse, builds on-the-fly charts, predicts trends and runs root-cause anomaly detection using SpotIQ, delivering finished analytical outputs rather than intermediate data. SpotterViz turns raw data into complete, styled dashboards without manual configuration, and the platform’s Analyst Studio adds SQL, Python and R for technical users who need more depth than conversational querying alone. ThoughtSpot connects directly to Snowflake, Databricks, BigQuery and Redshift without data extraction, inheriting warehouse security and governance by design. Pricing starts at $25 per user per month on Essentials, rising to around $50 on Pro with average enterprise contracts running between $100,000 and $500,000 annually, reflecting its enterprise positioning.
Features: Spotter AI Analyst for conversational natural language querying of warehouse data, SpotIQ automated anomaly detection, trend identification and correlation discovery, SpotterViz instant styled dashboard generation, Analyst Studio for SQL, Python and R analytical depth, direct warehouse connections to Snowflake, Databricks, BigQuery and Redshift, governance-aware querying inheriting warehouse access controls, embedded analytics capability, AI-generated narrative explanations of findings, and an enterprise pricing model with per-user and usage-based tiers.
Best for: enterprise organizations with clean, well-governed warehouse data whose primary goal is enabling non-technical business users to get analytical answers independently, reducing the volume of ad-hoc requests directed at data analyst teams.
Sigma Computing
Sigma Computing takes a distinctive approach to warehouse-native analytics by wrapping live cloud warehouse queries in a spreadsheet-like interface that business users find immediately familiar, rather than forcing them to learn a new dashboard paradigm or write SQL. Every analysis in Sigma runs live against Snowflake, Databricks, BigQuery or Redshift without data extraction or duplication, inheriting the warehouse’s security model and always reflecting current data. The April 2026 launch of Sigma Agents introduced autonomous AI agents capable of executing writes, triggering REST API calls, firing webhooks and interfacing with external systems like Salesforce, Jira and Slack directly from within an analysis workflow, moving Sigma from a visualization layer into an operational automation surface. The Ask Sigma natural language interface finds data sources and builds multi-step analyses while showing decision logic at each step, and Sigma’s MCP server support means it can be queried from any AI assistant interface. For business analysts comfortable with spreadsheet thinking who work on Snowflake or Databricks infrastructure, Sigma’s adoption speed, typically two to five days to productive use versus four to eight weeks for traditional BI tools, is a significant practical advantage.
Features: spreadsheet-like interface running live warehouse queries without data extraction, direct connections to Snowflake, Databricks, BigQuery and Redshift, Sigma Agents for autonomous write execution and external system integration, Ask Sigma natural language interface with visible decision logic, MCP server support for AI assistant connectivity, agentic AI formula assistance, inherited warehouse security and governance, collaborative workbooks with commenting and version history, and industry-recognized fast time-to-value for business analysts.
Best for: business analysts on Snowflake or Databricks infrastructure who are comfortable with spreadsheet thinking and want live warehouse analytics without learning a new dashboard paradigm, particularly teams that need fast time-to-productivity over deep customization.
Microsoft Fabric
Microsoft Fabric is Microsoft’s unified analytics platform launched in 2023 and now maturing into a comprehensive data estate layer that combines data engineering, data warehousing, real-time analytics, data science and business intelligence under one governed, lakehouse-based architecture built on OneLake storage. Rather than connecting multiple Azure services with custom integration work, Fabric provides a single SaaS environment where data engineers, analysts, data scientists and business users all work on the same underlying data without moving it between systems. The Copilot integration runs throughout Fabric’s workloads: it generates DAX and M code for Power BI analysts, writes Spark code for data engineers, drafts SQL for warehouse users, and provides natural language data exploration for business users, all drawing on the same governed dataset. Fabric’s inclusion in Microsoft 365 E5 agreements has accelerated enterprise adoption significantly, and the platform’s integration with the broader Microsoft security and compliance stack, including Purview for governance and Entra ID for access control, makes it a natural fit for organizations standardized on Microsoft. For data teams evaluating a new platform from scratch in 2026, Fabric is increasingly the default recommendation within the Microsoft ecosystem.
Features: unified lakehouse architecture on OneLake combining data engineering, warehousing, real-time analytics, data science and BI, Copilot AI assistance across all workloads including DAX, Spark, SQL and natural language querying, native Power BI integration with shared semantic models, Microsoft Purview governance and Entra ID access control, real-time event streaming with Eventstream, integration with the full Microsoft 365 and Azure ecosystem, a single SaaS environment eliminating cross-system data movement, and inclusion in Microsoft 365 E5 licensing for enterprises.
Best for: organizations already standardized on Microsoft infrastructure that are building or rebuilding their data platform and want a single unified environment covering the full data lifecycle from ingestion through analytics, without assembling a multi-vendor stack.
Tellius
Tellius is an agentic analytics platform built specifically to answer the question that most BI tools leave unanswered: not just what happened to a metric, but why it changed, in natural language, across billions of data points, without an analyst building a custom investigation. Its dual AI engine combines a search-based conversational interface for ad-hoc questions with an automated insight layer, Polaris AI, that continuously scans data for anomalies, root causes and key performance drivers and delivers finished explanations ranked by business impact. Where ThoughtSpot produces charts from natural language queries, Tellius produces analytical narratives: when a KPI drops, Tellius automatically decomposes the change into contributing factors, ranks them by magnitude and explains them in plain language that a business leader can act on without needing to interpret a chart. Frequently deployed in pharmaceutical, consumer packaged goods and financial services environments, Tellius has built specific commercial AI workflows around go-to-market analytics, trade promotion optimization and revenue growth management for organizations where those domain-specific analytical patterns recur at scale. Gartner Peer Insights reviews consistently highlight the platform’s root-cause analysis quality as its strongest differentiator.
Features: Polaris AI automated root-cause analysis and key driver detection across billions of data points, conversational natural language querying with persistent analytical context, proactive anomaly detection and performance monitoring, automated insight narratives explaining why metrics changed, domain-specific commercial AI workflows for pharma, CPG and financial services, an agentic layer automating repetitive analytical workflow steps, integration with major cloud warehouses and enterprise data sources, business-impact-ranked insight delivery, and Gartner Peer Insights recognition for root-cause analytics quality.
Best for: enterprise organizations in pharmaceuticals, consumer packaged goods and financial services that need automated, root-cause-level explanations of metric changes at scale, not just conversational chart generation, and that have recurring analytical patterns suited to domain-specific AI workflow automation.
DataGPT
DataGPT is a conversational analytics platform built around the premise that asking a business question should produce an analyst-level investigative answer, not a single chart, running multi-step investigations across thousands of statistical tests and query executions to deliver curated findings explaining why metrics changed rather than simply what they show. Its approach is architecturally closer to how an experienced senior analyst would investigate a complex business problem, planning a series of inter-related queries, running them in parallel and synthesizing results into a coherent narrative, than to the single-query text-to-SQL pattern of simpler conversational tools. DataGPT’s Data Navigator provides a self-serve exploration layer where business users can drill into metrics freely and investigate granular drivers without writing queries, and the platform delivers proactive daily insight summaries that monitor data continuously and surface emerging trends before they require a human to notice them. As a relatively young platform, DataGPT is best evaluated through a structured pilot against a real business question rather than a demo, to confirm that its multi-step investigation approach handles the specific analytical complexity of a given organization’s data.
Features: multi-step analytical investigations running thousands of queries and statistical tests per question, analyst-level findings explaining why metrics changed rather than generating single charts, proactive daily insight summaries with continuous data monitoring, Data Navigator for self-serve metric exploration and granular driver investigation, automated trend and anomaly detection with narrative explanations, pre-built connectors to major cloud warehouses, business-user-accessible interface without SQL or query knowledge, and an architecture designed for complex analytical depth beyond simple text-to-SQL translation.
Best for: data-forward organizations that want AI to conduct multi-step root-cause investigations on complex business questions, going substantially beyond chart generation from typed queries, and that are comfortable piloting a newer platform rather than a long-established enterprise vendor.
Julius AI
Julius AI is a consumer-grade conversational data analysis tool built around the simplest possible entry point: upload a CSV or Excel file, connect a Google Sheet, or link a database, ask a question in plain English and get a chart, summary or statistical analysis within seconds, with the Python code behind every analysis visible and editable. With more than two million users and pricing starting at $20 per month, Julius is one of the fastest-growing tools in the ad-hoc data exploration space, valued primarily by individual analysts, students and small teams who need analytical capability without the infrastructure overhead of an enterprise platform. Its warehouse connectivity to Snowflake, PostgreSQL and MySQL extends it meaningfully beyond pure file uploads, and the code transparency, being able to see and modify the Python behind any visualization, is a genuine differentiator for users who want to verify or extend what the AI produces. Julius is not a governed enterprise analytics platform: different users asking the same question on different sessions can receive different results because there is no semantic layer enforcing consistent metric definitions, which makes it unsuitable for organizational analytics where alignment on a shared version of truth matters. Its best role is as an individual accelerator for exploratory analysis and quick one-off investigations.
Features: conversational natural language interface on uploaded files, Google Sheets and connected databases, visible and editable Python code behind every analysis, broad file format support including CSV, Excel and JSON, basic warehouse connectivity to Snowflake, PostgreSQL and MySQL, fast chart and visualization generation from typed questions, statistical analysis and summary capabilities, pricing from $20 per month, no infrastructure setup required, and over two million users across individual analysts, students and small teams.
Best for: individual analysts, students and small teams needing fast, low-cost exploratory analysis on files or small databases, where the absence of a governed semantic layer is acceptable because results are reviewed by the analyst rather than shared as a single organizational source of truth.
Cloud Data Warehouses & Lakehouse Platforms
These are the storage and compute foundations on which every other analytics tool in this guide ultimately runs, providing the scalable infrastructure for centralizing, querying and processing data at any volume. Their differentiator ranges from separation of storage and compute for cost efficiency to unified lakehouse architectures that combine structured and unstructured data on one platform to extreme query speed on high-concurrency analytical workloads. Buyers are data engineering, analytics engineering and platform teams making foundational infrastructure decisions that will shape the entire analytics stack.
Snowflake
Snowflake pioneered the separation of compute and storage in cloud data warehousing, letting organizations store data cost-effectively in cloud object storage while spinning up and suspending compute warehouses independently, a model that solved the chronic over-provisioning problem of traditional on-premises data warehouses. Now positioned as the AI Data Cloud, Snowflake has extended well beyond warehousing into data sharing through Snowflake Marketplace, application development through Snowpark, and AI through Cortex AI, which provides vector search, LLM inference and SQL-based AI functions directly inside the warehouse without data movement. Snowflake Cortex Analyst and the Cortex AI suite bring natural language querying, sentiment analysis and document processing into SQL workflows, making Snowflake increasingly a platform where analytical and AI workloads converge rather than requiring separate systems. The platform’s broad BI tool integration, with native connectors to virtually every major BI and analytics tool, makes it the most commonly chosen warehouse by organizations building a multi-tool modern data stack. Consumption-based pricing on compute credits means costs can vary significantly with workload volume, and careful warehouse sizing and auto-suspend configuration are essential for cost control at scale.
Features: separated compute and storage architecture with independent scaling, Snowflake Cortex AI for LLM inference, vector search and AI functions in SQL, Snowpark for Python, Java and Scala data engineering, Snowflake Marketplace for data sharing and third-party data access, Cortex Analyst for natural language querying, native integration with dbt, Fivetran, Tableau, Looker and virtually all major analytics tools, multi-cloud availability across AWS, Azure and Google Cloud, consumption-based pricing on compute credits, and the most broadly supported warehouse across the modern analytics ecosystem.
Best for: organizations building a best-of-breed multi-tool analytics stack that needs maximum compatibility with BI, transformation and AI tooling, and that prioritize the flexibility of a neutral, broadly supported warehouse over the depth of integration offered by a single-vendor ecosystem like Microsoft Fabric or Google BigQuery.
Databricks
Databricks was built by the creators of Apache Spark and remains the definitive platform for organizations that need to run data engineering, machine learning and analytics on one unified lakehouse architecture rather than maintaining separate data warehousing and ML infrastructure. Its Delta Lake open table format provides ACID transaction guarantees on data lake storage, and Unity Catalog provides centralized governance, lineage and access control across all Databricks workloads whether data engineering, SQL analytics or ML model training. Databricks Mosaic AI unifies the AI layer, providing an AI assistant for code generation, Databricks Genie for natural language SQL querying, AutoML for automated model training and a full model serving infrastructure, making Databricks increasingly the platform where data science and data analytics converge at large scale. The recent merger announcement between Databricks and Fivetran signals a push toward unified open data infrastructure spanning ingestion through transformation and into analytics. Compared with Snowflake, Databricks is generally the stronger choice when ML and unstructured data processing are core requirements alongside SQL analytics; for organizations doing primarily SQL-based BI on relational data, Snowflake’s operational simplicity and broader BI tool integration often wins.
Features: Apache Spark-native lakehouse architecture on Delta Lake with ACID transactions, Unity Catalog for centralized governance, lineage and access control, Databricks Mosaic AI with code assistant, Genie natural language SQL querying and AutoML, Spark-based data engineering at scale, MLflow for experiment tracking and model management, model serving infrastructure for production ML deployment, notebooks in Python, SQL, R and Scala, integration with Fivetran, dbt and major BI tools, and a strong fit for workloads combining data engineering, ML and analytics on the same platform.
Best for: data and ML engineering teams that need to combine large-scale data processing, machine learning model training and SQL analytics on one unified platform, particularly organizations handling unstructured data alongside structured, or building production ML systems alongside their analytical workflows.
Google BigQuery
Google BigQuery is Google Cloud’s fully managed, serverless data warehouse with no infrastructure to configure or maintain, providing automatic scaling from kilobytes to petabytes and a pricing model that charges for storage and query execution rather than provisioned capacity. BigQuery’s columnar storage and massively parallel query engine deliver fast performance on extremely large datasets, and its integration with the rest of Google Cloud’s AI and analytics stack, including Vertex AI, Looker and Gemini, makes it the natural warehouse choice for organizations standardized on Google Cloud. BigQuery ML lets analysts run machine learning models using SQL directly inside the warehouse without moving data to a separate ML platform, and BigQuery Omni extends the warehouse to query data residing in AWS S3 or Azure Blob Storage without replication. The platform’s serverless architecture and per-query pricing can deliver lower total cost of ownership than provisioned warehouses for organizations with variable or unpredictable workload patterns, though high-volume, consistent workloads often benefit from flat-rate or edition-based pricing. For organizations on Google Cloud or primarily using Google-ecosystem tools including Looker, GA4 and Google Workspace, BigQuery is typically the lowest-friction warehouse foundation.
Features: fully serverless architecture with automatic scaling and no infrastructure management, columnar storage with massively parallel query execution, BigQuery ML for machine learning directly in SQL, BigQuery Omni for querying data in AWS and Azure without replication, Gemini integration for natural language querying and AI-assisted analysis, Looker native integration, per-query pricing with flat-rate and edition options, Google Cloud Vertex AI integration for advanced ML, built-in data sharing and analytics hub, and strong fit for organizations using the Google Cloud and Google Workspace ecosystem.
Best for: organizations standardized on Google Cloud, or primarily using Google-ecosystem analytics tools like Looker and GA4, that want a fully managed, serverless warehouse requiring minimal infrastructure engineering and scaling automatically with workload demand.
Amazon Redshift
Amazon Redshift is Amazon’s fully managed cloud data warehouse, one of the earliest cloud warehouses on the market and still heavily adopted across AWS-centric organizations, providing a columnar query engine tightly integrated with the broader AWS analytics and storage ecosystem including S3, Glue, Athena, Lambda and Kinesis. Redshift Serverless removes the need to provision and manage cluster sizes for teams with variable workloads, while Redshift Spectrum allows queries to run directly against data in S3 without loading it into the warehouse. For organizations already deeply committed to AWS infrastructure, Redshift’s integration depth and the operational familiarity of AWS-managed services can outweigh the broader BI ecosystem compatibility advantage of Snowflake. Against newer entrants, Redshift’s operational complexity, including the need to manage distribution keys, sort keys and vacuuming for optimal performance, is frequently cited as a reason organizations migrate to Snowflake or BigQuery when rebuilding their stack, particularly those without dedicated data engineering resources.
Features: columnar storage optimized for analytical query performance on large datasets, Redshift Serverless for automatic scaling without cluster management, Redshift Spectrum for querying S3 data directly without loading, native integration with the full AWS analytics ecosystem, RA3 nodes with managed storage separating compute and storage costs, machine learning via Redshift ML with Amazon SageMaker, federated querying across RDS, Aurora and S3, strong integration with AWS Glue, Lake Formation and Kinesis, and deep existing adoption across AWS-native organizations.
Best for: AWS-native organizations with existing Redshift investments or deep AWS infrastructure dependencies, particularly those with dedicated data engineering resources comfortable managing Redshift’s distribution and query optimization requirements.
ClickHouse
ClickHouse is an open-source column-oriented database management system built specifically for real-time analytical queries at extremely high ingestion rates, delivering sub-second query performance on billions of rows in scenarios where general-purpose warehouses like Snowflake or BigQuery would require query optimization or caching to achieve comparable latency. Originally developed at Yandex for web analytics workloads and open-sourced in 2016, ClickHouse has become the go-to database for event-driven analytics, time-series workloads, operational analytics and any use case requiring both high write throughput and low query latency simultaneously. ClickHouse Cloud, the managed offering, removes the infrastructure management burden of self-hosted deployments while preserving the performance characteristics. Its integration with the analytics ecosystem is narrower than Snowflake or BigQuery, and it lacks the semantic modeling, governance and BI-layer sophistication of a full data warehouse platform, positioning it most clearly as a specialized high-performance component within a broader analytics architecture rather than a standalone analytics platform. For product analytics at scale, operational dashboards requiring sub-second refresh and log analytics workloads, ClickHouse is frequently the highest-performance option available.
Features: columnar storage with sub-second query performance on billions of rows, extremely high write throughput for real-time event ingestion, compression ratios that significantly reduce storage costs versus row-oriented databases, ClickHouse Cloud managed offering removing infrastructure burden, open-source Apache license for self-hosted deployments, SQL interface compatible with standard analytics tooling, strong fit for time-series, event-driven and operational analytics workloads, wide adoption in product analytics and log analytics use cases, and integration with dbt, Grafana and common modern data stack tooling.
Best for: engineering and data teams that need sub-second analytical query performance on high-velocity event data, time-series workloads or operational dashboards where general-purpose cloud warehouses introduce latency that real-time use cases cannot tolerate.
Data Integration, Transformation & Orchestration
These tools handle the engineering layer between raw data sources and the analytics platforms that query it, covering data movement, cleaning, modeling and pipeline scheduling. Their differentiator spans from zero-maintenance managed connectors with schema-change handling to SQL-based transformation frameworks with software engineering best practices to visual ETL builders for less technical teams. Buyers are data engineers, analytics engineers and data platform teams responsible for keeping data pipelines reliable, current and auditable.
Fivetran
Fivetran is the market leader in managed data movement, providing more than 500 pre-built connectors that automatically extract data from SaaS applications, databases, event streams and files and load it into cloud data warehouses with zero connector maintenance. Its key value proposition is reliability: Fivetran handles API changes, schema evolution, incremental sync logic and failure recovery automatically, replacing the engineering cycles that teams would otherwise spend maintaining custom ingestion pipelines. The recently announced merger with dbt Labs signals a strategic push toward unified open data infrastructure, positioning the combined company as a neutral alternative to the single-vendor suites offered by Snowflake, Databricks and Google. Fivetran’s consumption-based pricing on Monthly Active Rows has been a source of concern for data teams with high-volume sources, and careful connector configuration is essential for cost control. For organizations prioritizing connector reliability and breadth over cost optimization, Fivetran remains the default managed ingestion choice.
Features: 500-plus pre-built connectors with automatic schema evolution and API change handling, managed incremental sync with change data capture, zero connector maintenance engineering burden, log-based CDC for low-impact real-time database replication, automatic failure recovery and alerting, native integration with Snowflake, BigQuery, Databricks and Redshift, dbt Cloud integration for end-to-end pipeline coordination, consumption-based Monthly Active Row pricing, enterprise security and compliance certifications, and the broadest managed connector library in the market.
Best for: data teams prioritizing connector reliability and breadth over cost optimization, who want to eliminate the engineering overhead of maintaining custom ingestion pipelines across many data sources, and for organizations building on Snowflake or Databricks where Fivetran’s native integration is a meaningful operational advantage.
dbt Labs
dbt Labs has become the de facto standard for SQL-based data transformation in the modern data stack, introducing software engineering practices including version control, automated testing and comprehensive documentation to a discipline that was previously managed through ad-hoc SQL scripts and undocumented warehouse stored procedures. dbt’s transformation-in-the-warehouse approach runs SQL models directly on Snowflake, BigQuery, Databricks, Redshift and other supported warehouses rather than moving data to a separate transformation engine, keeping everything in the governed warehouse environment. dbt Cloud adds a managed scheduler, a development IDE, CI/CD pipelines and the dbt Semantic Layer, a centralized metric definition layer that lets multiple BI tools query the same governed metric definitions without duplicating business logic. The announced merger with Fivetran is intended to create an integrated ingestion-to-transformation platform covering the middle layers of the modern data stack. dbt Core, the open-source version, is free and widely adopted, while dbt Cloud’s pricing reflects its role as a production management layer on top of the core transformation framework.
Features: SQL-based transformation with software engineering practices including version control, automated testing and documentation, direct warehouse-native execution on Snowflake, BigQuery, Databricks, Redshift and others, dbt Semantic Layer for centralized governed metric definitions used across multiple BI tools, dbt Cloud managed scheduler, development IDE and CI/CD pipelines, an active open-source community with extensive package ecosystem, data lineage visualization, model dependency management, integration with Fivetran, Airflow and major orchestration tools, and the de facto standard transformation framework in the modern data stack.
Best for: analytics engineers and data teams that want to bring software engineering discipline to SQL transformation, with version control, testing and documentation as standard practice, and that need a centralized semantic layer ensuring consistent metric definitions across multiple downstream BI tools.
Airbyte
Airbyte is the leading open-source ELT platform with more than 350 pre-built connectors, positioned as the most direct open-source alternative to Fivetran’s managed offering. Self-hosted Airbyte is free, which is its defining economic advantage for cost-constrained teams, and the Connector Development Kit makes building custom connectors for unsupported sources significantly more accessible than building comparable Fivetran connectors. Airbyte Cloud and Airbyte Enterprise provide managed hosting for teams that want the connector breadth without the infrastructure management, though Fivetran’s connector reliability and schema-change handling are generally regarded as more robust for production environments serving critical data pipelines. The practical Airbyte vs Fivetran decision often comes down to whether the engineering budget for managing infrastructure and handling connector edge cases is lower than the incremental cost of Fivetran’s managed service; many teams start on Airbyte and migrate high-volume or high-criticality connectors to Fivetran as their stack matures.
Features: 350-plus open-source connectors with free self-hosted deployment, Connector Development Kit for building custom connectors, Airbyte Cloud and Enterprise for managed hosting, change data capture support, a visual UI for configuring syncs without code, integration with Snowflake, BigQuery, Databricks and Redshift destinations, active open-source community with frequent connector additions, lower cost than Fivetran for high-volume connectors on self-hosted deployments, and broad adoption among cost-conscious startups and engineering-led data teams.
Best for: cost-constrained teams and engineering-led organizations comfortable managing Docker or Kubernetes infrastructure, particularly those needing custom connectors for non-standard sources that Fivetran’s catalog does not cover, or startups optimizing data infrastructure spend before justifying Fivetran’s managed pricing.
Apache Airflow
Apache Airflow is the most widely deployed open-source workflow orchestration platform in the data engineering community, defining pipelines as directed acyclic graphs in Python code that schedule, monitor, retry and alert on complex interdependent data processes. Originally developed at Airbnb in 2014 and now an Apache Software Foundation project, Airflow’s massive community has contributed thousands of operators covering cloud services, databases, messaging systems and ML frameworks, making it the broadest integration surface of any orchestrator. Astronomer provides a managed Airflow-as-a-service that removes the infrastructure burden of running Airflow at production scale, while AWS MWAA and Google Cloud Composer offer cloud-native managed Airflow environments. Newer orchestrators including Dagster and Prefect have emerged as alternatives with better developer experience and asset-centric pipeline modeling, and the Airflow community continues to evolve with Airflow 3.0 introducing significant architectural improvements. For teams with existing Airflow investments or those needing the broadest possible operator ecosystem, Airflow remains the default choice; for teams starting fresh, Dagster’s modern approach is increasingly recommended.
Features: directed acyclic graph pipeline definition in Python code, an extensive operator library covering cloud services, databases and ML frameworks, a monitoring UI for pipeline execution, retry and alert management, the Airflow community’s broad ecosystem of integrations, Astronomer managed cloud for removing infrastructure burden, AWS MWAA and Google Cloud Composer native managed options, native integration with dbt, Spark, Fivetran and major data tools, strong adoption across the data engineering community, and the broadest orchestration operator ecosystem available.
Best for: data engineering teams with complex, interdependent multi-step pipelines requiring robust scheduling, monitoring and retry logic, particularly those already invested in Airflow’s ecosystem or needing the breadth of its operator library to cover unusual integration requirements.
Matillion
Matillion provides a cloud-native ELT and data transformation platform positioned at mid-enterprise teams that need a visual, low-code approach to data pipeline building rather than the code-first workflows of dbt or custom Airflow DAGs. Its Matillion Data Productivity Cloud combines data integration, data transformation with a visual canvas and an AI-assisted approach to pipeline building, including Copilot features that generate transformation logic from natural language descriptions. Matillion runs transformations directly in the target warehouse, consistent with the ELT paradigm, and its native integrations with Snowflake, BigQuery, Databricks and Redshift position it clearly within the modern data stack. The platform targets data teams that include business analysts and less technical practitioners alongside data engineers, since the visual canvas is accessible to users who would struggle with dbt’s SQL-and-YAML code-first workflow. Compared with Fivetran and dbt assembled separately, Matillion offers a more integrated but less modular alternative that trades some flexibility for a more unified development experience.
Features: visual low-code data pipeline canvas accessible to non-engineer practitioners, native ELT execution in the target warehouse without an intermediate processing layer, AI Copilot for natural language transformation logic generation, data integration and transformation in one platform, native connectors to Snowflake, BigQuery, Databricks and Redshift, collaborative pipeline development with version control, pre-built transformation components for common data patterns, and a mid-enterprise positioning between startup-friendly tools and heavy enterprise ETL suites.
Best for: mid-enterprise data teams that include less technical practitioners alongside data engineers and want a visual, low-code pipeline builder that runs ELT directly in the warehouse, rather than the pure code-first workflows of dbt or custom orchestration tooling.
Qlik Talend
Qlik Talend is the data integration platform that resulted from Qlik’s acquisition of Talend in 2023, combining Talend’s long-established enterprise data integration and data quality tooling with Qlik’s analytics ecosystem. Talend Data Fabric, now operating under the Qlik umbrella, provides data integration, data quality, master data management and data cataloging capabilities that position it as a broader data management suite rather than a pure ELT tool. Its strength lies in organizations with complex, heterogeneous data environments that need robust data quality checks, master data management and integration spanning both cloud and legacy on-premises systems, scenarios where lighter-weight cloud-native ELT tools like Fivetran or Airbyte offer insufficient governance and quality management depth. The Qlik integration has added analytical context alongside the integration tooling, though the combined product roadmap is still maturing following the acquisition. For organizations already using Talend on-premises that are evaluating a cloud migration path, the Qlik Talend evolution provides continuity while adding cloud-native capabilities.
Features: enterprise data integration across cloud and on-premises environments, data quality profiling, cleansing and standardization, master data management for consistent entity definitions, data catalog integration following the Qlik acquisition, support for complex heterogeneous source systems including legacy on-premises, pipeline monitoring and data lineage, integration with Snowflake, BigQuery and other cloud warehouses, Qlik analytics ecosystem connectivity, and a long track record in regulated enterprise environments.
Best for: enterprises with complex legacy data environments, strong data quality and master data management requirements, or existing Talend on-premises investments seeking a cloud migration path that preserves existing integration and governance investments.
Data Governance, Cataloging & Observability
These platforms manage the trust layer of the analytics stack, cataloging data assets, documenting lineage, enforcing access policies and monitoring pipeline health so that every downstream consumer, whether a business user or an AI agent, can rely on data being accurate, understood and properly governed. Their differentiator ranges from compliance-grade formal policy stewardship to modern-stack-native active metadata platforms to ML-powered data observability that catches quality incidents before they corrupt dashboards. Buyers are data governance leads, analytics engineers and data platform teams in organizations where data trust has become a measurable business risk.
Atlan
Atlan is the 2026 Gartner Magic Quadrant Leader and Forrester Wave Leader for data governance, having built its position by designing a modern, cloud-native data catalog specifically for the modern data stack era rather than retrofitting enterprise governance software from the legacy BI era. Its Context Layer architecture connects business definitions, lineage, quality signals, governance policies and ownership metadata across 100-plus source systems including dbt, Snowflake, Databricks, Fivetran, Airflow, Tableau and Looker into one traversable graph that both human users and AI agents can query. Atlan’s deployment speed, typically functional in a few weeks for mid-sized teams versus six to twelve months for legacy incumbents, and its Notion-like collaborative interface have driven high adoption rates within data teams that have historically struggled to get analysts and engineers to engage with governance tooling. Its AI agents surface relevant metadata, ownership information and quality signals at the moment a user is working with a data asset, rather than requiring them to navigate a separate governance portal. The platform is increasingly positioned as the governance substrate that makes agentic AI analytics reliable, since AI agents querying warehouse data can only produce trustworthy answers if the definitions and lineage they read are governed and current.
Features: Gartner MQ and Forrester Wave Leader for data governance in 2026, Context Layer connecting metadata, lineage, quality and governance across 100-plus integrations, fast deployment in weeks versus months for legacy alternatives, AI-native active metadata surfaced at the point of use, built-in column-level lineage with no additional setup, native integrations with dbt, Snowflake, Databricks, Tableau, Looker and Fivetran, Data Quality Studio aggregating signals from Monte Carlo and Soda, support for data mesh and data product ownership models, and a collaborative Notion-like interface driving high user adoption.
Best for: data teams on the modern data stack that want a governance and cataloging platform deploying in weeks rather than months, with high user adoption among engineers and analysts, and that are positioning their governance layer to serve both human users and AI agents querying their warehouse.
Collibra
Collibra is the governance platform of record for heavily regulated industries including financial services, healthcare and government, where formal policy stewardship, auditable lineage documentation and compliance artifact generation are regulatory requirements rather than optional best practices. Its centralized policy stewardship model, with explicit approval chains, data stewardship roles and compliance workflow automation, reflects an architecture designed for environments where governance is a legal discipline managed by dedicated professionals rather than a collaborative cultural practice across a data team. Collibra Data Intelligence Platform now includes data quality and observability capabilities alongside catalog, glossary and lineage, covering a broader scope of the governance stack than the catalog-only positioning of earlier releases. Standard tier pricing starts at approximately $122,600 annually for twenty creator users, and large enterprise implementations regularly exceed $500,000 including implementation services and can take six to twelve months to reach full production. For organizations in regulated industries with the budget, timeline and governance maturity to justify a Collibra deployment, it remains the reference standard for formal enterprise data governance.
Features: formal policy stewardship with explicit approval chains and compliance artifact generation, enterprise data catalog with business glossary and term management, column-level data lineage across complex multi-system environments, integrated data quality and observability in the Collibra DQ module, workflow automation for governance processes including stewardship assignments and policy approvals, GDPR, CCPA and financial regulation compliance tooling, SAP and Oracle ecosystem integration, strong regulatory industry track record in financial services, healthcare and government, and professional services depth for complex enterprise implementations.
Best for: regulated enterprises in financial services, healthcare and government with dedicated data governance programs, substantial implementation budgets, and regulatory requirements that mandate formal documented lineage, policy stewardship and compliance artifact generation.
Alation
Alation pioneered the enterprise data catalog category and remains particularly strong in analytics-first organizations where the primary use case is helping data analysts and business users find, understand and trust the data they are working with, rather than managing formal governance workflows for regulatory compliance. Its collaborative, wiki-like approach to data documentation encourages analysts and data owners to contribute descriptions, stewardship information and usage context directly alongside data assets, which drives higher voluntary adoption rates than more process-heavy governance platforms. Alation’s Open Connector Framework and Open Data Quality Framework support integration with a range of modern stack tools and quality platforms including Monte Carlo and Soda, and the platform has added AI features that suggest metadata, surface relevant assets during search and automate parts of the documentation burden. GigaOm analysis estimated mid-market Alation deployments at approximately $413,000 including connectors and integrations, positioning it at a similar investment level to Collibra for mid-enterprise customers. For organizations that do not need Collibra’s formal regulatory governance apparatus but want a mature, analyst-friendly catalog with strong enterprise support, Alation is the most common alternative.
Features: collaborative wiki-like data documentation encouraging broad user contribution, strong enterprise data catalog with business glossary and stewardship workflows, Open Connector Framework for modern stack integration, Open Data Quality Framework for quality platform integration, AI-assisted metadata suggestions and asset recommendations, query history and usage analytics showing which data assets are most queried, SaaS and customer-managed deployment options, a track record among analytics-first organizations prioritizing adoption, and analyst-friendly search and discovery UX.
Best for: analytics-first organizations that want a mature, enterprise-grade data catalog where driving adoption among analysts and business users is the primary goal, and that do not need the formal regulatory governance apparatus of Collibra.
Monte Carlo
Monte Carlo is the industry-leading data observability platform, applying ML-powered anomaly detection to monitor data freshness, volume, schema and distribution across warehouses, BI tools and data pipelines, automatically detecting data quality incidents that would otherwise corrupt downstream dashboards and analytical outputs before anyone noticed. Rather than writing explicit quality tests for every column and table, Monte Carlo’s ML engine learns what normal looks like for each data asset and flags deviations automatically, covering the large proportion of data quality issues that no one thought to write a test for. The platform integrates with Snowflake, Databricks, BigQuery, Redshift and major BI tools, providing end-to-end lineage that shows exactly which dashboards and downstream consumers are affected when a pipeline incident occurs, enabling rapid impact assessment and root-cause investigation. Monte Carlo’s relationship with Atlan positions it as a complementary detection layer feeding quality signals into Atlan’s governance control plane, where incidents are routed to the right owner with full context. For enterprise data teams where data downtime, meaning dashboards surfacing wrong numbers because of upstream pipeline failures, is a significant operational risk, Monte Carlo is typically the first observability tool evaluated.
Features: ML-powered automated anomaly detection on data freshness, volume, schema and distribution, end-to-end data lineage showing downstream impact of incidents across warehouses and BI tools, automatic coverage of data quality issues without explicit test definition, integration with Snowflake, Databricks, BigQuery, Redshift and major BI platforms, incident routing with lineage context to the responsible data owner, a field-level lineage graph for root-cause investigation, SLA monitoring and alerting, integration with dbt, Airflow and Fivetran for full-stack visibility, and established market leadership in the data observability category.
Best for: data engineering and platform teams responsible for the reliability of production data pipelines, where data quality incidents corrupting downstream dashboards carry significant business or reputational risk, and where manual test coverage alone is insufficient to catch the full range of pipeline failures.
Microsoft Purview
Microsoft Purview is Microsoft’s unified data governance service covering data cataloging, classification, lineage and policy enforcement across Azure-native and hybrid environments, with native scanning of Azure Data Lake, Blob Storage, Synapse, SQL Server, Fabric and the broader Microsoft data estate alongside non-Azure sources through connectors. Its consumption pricing model, approximately $0.50 per governed asset per day, creates variable costs that scale with governance scope, which can disincentivize comprehensive coverage for cost-conscious teams but avoids the large upfront license commitments of Collibra or Alation. Purview’s deepest value is in organizations standardized on Microsoft infrastructure, where it provides governance visibility into the data flowing through Fabric, Azure and Microsoft 365 without requiring a separate vendor relationship. Its AI-ready governance capabilities, including Copilot integration for metadata generation and policy management, align it with Microsoft’s broader AI strategy of grounding Copilot answers in governed, trusted enterprise data. For organizations outside the Azure ecosystem or with non-Microsoft-primary data infrastructure, Purview’s connector coverage for non-Azure sources is narrower than Atlan or Alation.
Features: native scanning and cataloging of Azure data services including Fabric, Synapse, Data Lake, Blob Storage and SQL Server, unified governance across Azure-native and hybrid environments, data classification and sensitivity labeling for compliance, policy enforcement through Microsoft Information Protection, Copilot integration for AI-assisted metadata and policy management, consumption-based pricing avoiding large upfront license commitments, Microsoft Entra ID integration for identity and access governance, non-Azure source scanning through connectors, and tight integration with the broader Microsoft security and compliance stack.
Best for: organizations standardized on Microsoft Azure and Fabric that want data governance coverage native to their existing Microsoft infrastructure, without introducing a separate governance vendor, and particularly those where Purview’s integration with Microsoft’s broader security and compliance stack is a meaningful operational advantage.
Product & Digital Experience Analytics
These platforms track what users do inside digital products, capturing event-based behavioral data to answer questions about feature adoption, retention cohorts, funnel completion and session-level experience that neither web analytics tools nor business intelligence platforms were designed to address. Their differentiator spans from deep funnel and cohort analysis for product managers to session replay and heatmaps for UX teams to open-source self-hosted deployments for privacy-sensitive organizations. Buyers are product managers, growth engineers and UX researchers at companies whose primary asset is a digital product.
Amplitude
Amplitude is the premium product analytics platform for scaling companies that need the broadest combination of behavioral analysis, predictive analytics, built-in A/B experimentation and data governance in a single tool. Its Spark AI lets users ask natural language questions about retention, feature adoption and cohort behavior, translating queries into analyses and surfacing explanations alongside results, and its predictive analytics layer applies ML to forecast which users are likely to convert or churn based on behavioral signals. Amplitude Analytics is available at multiple tiers from a free Starter plan through custom Enterprise pricing, with the Growth plan handling the mid-market range and the platform scaling to support enterprises processing hundreds of millions of events per month. For organizations evaluating their first product analytics platform, Amplitude is the most common enterprise recommendation; its main criticism is a steeper learning curve than Mixpanel and higher cost per monthly tracked user at scale.
Features: event-based product analytics with funnel analysis, retention curves and cohort tracking, Spark AI natural language querying of behavioral data, built-in A/B experimentation with statistical significance, predictive analytics for conversion and churn forecasting, session replay and heatmaps, behavioral cohort builder, Amplitude Data for taxonomy governance, integration with Snowflake, BigQuery, Redshift and Salesforce, a free Starter plan scaling to custom Enterprise pricing, and the broadest combined platform depth among product analytics tools.
Best for: scaling companies from Series A through enterprise that want the deepest combination of behavioral analytics, experimentation and AI-powered predictive analysis in one platform, and that have the budget and analytical maturity to take advantage of Amplitude’s full depth.
Mixpanel
Mixpanel is Amplitude’s closest competitor in product analytics, distinguished by a user-centric data model that puts the person at the center of every query rather than the event, making questions like how do power users in week one behave differently from churned users more natural to ask and faster to answer. Its Spark AI translates plain English product analytics questions into funnel, retention and cohort analyses, and Mixpanel’s generally faster implementation timeline, around two to four weeks versus Amplitude’s four to six weeks, makes it a frequent first choice for B2B SaaS teams that want focused event analytics without platform breadth. Pricing is event-based rather than user-based, which can deliver meaningful cost advantages for products with many users but moderate per-user event volume. The platform integrates with Snowflake, BigQuery and major data destinations, and its EU data residency, SOC 2 Type II and HIPAA support cover most enterprise compliance requirements.
Features: user-centric behavioral analytics with funnel, retention and cohort analysis, Spark AI natural language querying for product analytics questions, event-based pricing for cost predictability with many users, faster implementation timeline than Amplitude, EU data residency and HIPAA compliance, integration with Snowflake, BigQuery and major data warehouses, session replay, JQL for advanced custom queries, a free plan with event limits, and a strong reputation for intuitive UI accessible to non-technical product managers.
Best for: B2B SaaS teams that want focused funnel, retention and cohort analytics without the full platform breadth of Amplitude, particularly those with many users and moderate per-user event volumes where event-based pricing delivers cost advantages over monthly tracked user models.
PostHog
PostHog is the only product analytics platform on this list that is fully open-source and self-hostable, bundling product analytics, session replay, feature flags and A/B testing in a single platform with deployment options ranging from PostHog Cloud’s generous free tier to fully self-hosted infrastructure giving engineering teams complete control over where behavioral data lives. This data sovereignty angle is PostHog’s most distinctive characteristic: organizations with strict data residency requirements, healthcare or financial services compliance constraints, or philosophical commitments to data control can run a complete product analytics stack on their own infrastructure at zero software license cost. PostHog’s Max AI assistant answers behavioral questions in natural language and explains its reasoning, and HogQL, its SQL-like query language, gives technical users direct access to the underlying event data for custom analyses that the pre-built interfaces do not cover. The platform’s pricing on the cloud version is usage-based per product, providing maximum flexibility but requiring separate modeling of each capability’s cost.
Features: open-source and self-hostable product analytics with full data sovereignty, bundled session replay, feature flags and A/B experimentation in one platform, PostHog Max AI for natural language analytics queries, HogQL SQL-like query language for custom analysis, a generous cloud free tier covering one million events and 5,000 session recordings monthly, usage-based per-product cloud pricing, strong compliance positioning for healthcare and financial services self-hosted deployments, active open-source community with regular feature releases, and particular adoption among engineering-led, privacy-conscious and developer-tool companies.
Best for: engineering-led organizations with data sovereignty requirements, privacy compliance constraints, or cost structures that make open-source self-hosting preferable to commercial SaaS pricing, and for developer-tool companies whose users expect data control as a product characteristic.
Heap
Heap takes a fundamentally different approach to event tracking than Amplitude, Mixpanel or PostHog by automatically capturing every user interaction, every click, tap, swipe, form submission and page view, without requiring engineers to pre-define events before they can be analyzed. This autocapture model means product teams can retroactively analyze user behavior on interactions that were never explicitly instrumented, which is particularly valuable when a product ships a new feature and the team realizes they forgot to add tracking before launch. AI-driven path analysis surfaces the routes through the product that most strongly correlate with conversion or retention without requiring the analyst to hypothesize which paths matter first. Heap integrates with Snowflake, BigQuery and other warehouses for data export, and its session replay capability provides qualitative context alongside the quantitative behavioral data. The tradeoff of autocapture is a tendency toward data volume and noise: every automatically captured event requires governance effort to label, filter and structure before it can support reliable analysis, and organizations with limited data engineering resources can find the resulting data model difficult to maintain cleanly.
Features: autocapture of all user interactions without pre-defined event instrumentation, retroactive behavioral analysis on events that were never explicitly tracked, AI-driven path analysis correlating routes through the product with conversion and retention, session replay for qualitative context alongside quantitative data, integration with Snowflake, BigQuery and Redshift for data export, funnel, retention and cohort analysis on autocaptured data, mobile and web coverage, Heap Connect for warehouse data export, and the fastest implementation timeline in the category due to autocapture eliminating tracking setup.
Best for: product teams without dedicated analytics engineering resources who want to start analyzing behavior without instrumentation setup, and particularly teams that frequently ship new features and need the ability to retroactively analyze interactions on features that were not tracked before launch.
Pendo
Pendo positions itself as a product experience platform where analytics is the foundation for action rather than an end in itself: behavioral data collected by Pendo’s analytics layer directly triggers in-app guidance, walkthroughs, onboarding checklists and targeted feature announcements delivered to specific user segments without requiring engineering involvement. This analytics-to-engagement loop, where a cohort that has not adopted a key feature receives a targeted in-app tooltip, is Pendo’s core differentiator relative to pure analytics platforms where the insight and the action exist in separate systems. Its visual design studio lets product managers define trackable elements by clicking on them in the product interface through a browser extension, creating analytics without writing tracking code, and its analytics cover both quantitative behavioral metrics and qualitative NPS and survey data in one platform. For organizations that want to close the gap between understanding product behavior and acting on it through in-app experiences without engineering tickets, Pendo’s bundled approach is frequently more operationally efficient than pairing a separate analytics platform with a separate in-app messaging tool.
Features: product analytics with funnel, retention and feature adoption tracking, in-app guidance including walkthroughs, tooltips, onboarding checklists and announcements triggered by behavioral data, a visual design studio for defining trackable elements without writing code, NPS and in-app survey collection alongside quantitative behavioral data, segmentation for targeted in-app experiences by user behavior, PX product experience module for enterprise-scale in-app engagement, integration with Salesforce, HubSpot and major CRM platforms, and a bundled analytics-to-action workflow eliminating the need for a separate in-app messaging tool.
Best for: product teams whose primary goal is closing the loop between behavioral insight and in-app action, such as driving feature adoption or guided onboarding, where the operational efficiency of a single platform handling analytics, guidance and surveys outweighs the depth of a specialist analytics tool.
Fullstory
Fullstory is a digital experience intelligence platform built around session replay and behavioral data capture, giving product and engineering teams the ability to watch exactly how a real user navigated a product, where they paused, what they clicked, what errors they encountered and where they dropped off, in a pixel-perfect replay of their actual session. This qualitative depth is Fullstory’s primary differentiator: while platforms like Amplitude and Mixpanel excel at quantitative behavioral questions about cohorts and funnels at scale, Fullstory specializes in the qualitative investigation of individual sessions and small-sample UX problems that aggregate data cannot surface. Its DX Data model automatically indexes all captured interactions, making sessions searchable after the fact by behavior, error, rage click or frustration signal without requiring pre-defined event tracking. Fullstory also provides aggregated funnel and friction analytics, and AI-powered summaries that translate session patterns into plain-language insights, making it accessible to non-technical design and CX stakeholders alongside engineering teams.
Features: pixel-perfect session replay with clickstream, scroll, hover and error capture, DX Data automatic indexing of all interactions for retroactive behavioral search, funnel and friction analytics built on captured session data, AI-powered session summaries and pattern explanations, rage-click and frustration signal detection, heatmaps and aggregated interaction visualizations, privacy controls for masking PII in session recordings, integration with Amplitude, Mixpanel and major product analytics platforms, and a particular strength for UX research and debugging complex product flows.
Best for: product and engineering teams that need to understand the qualitative experience of individual users or small segments navigating specific flows, where watching actual sessions provides insights that aggregate funnel metrics cannot reveal, and for UX researchers conducting behavioral studies alongside quantitative analytics.
Contentsquare
Contentsquare is a digital experience analytics platform focused on understanding how visitors interact with web and mobile content at a visual and spatial level, using zoning analytics, journey analysis, heatmaps and session replay to surface content engagement patterns that page-level traffic metrics completely miss. Its AI layer, CS Ai, automatically analyzes billions of digital interactions to surface insights about which content zones drive engagement, which create frustration and which are simply ignored by visitors, generating recommendations that conversion rate optimization and UX teams can act on without building custom analyses. Contentsquare is deployed primarily by large e-commerce, retail, financial services and travel brands with high web traffic volumes where small improvements in content engagement or checkout flow translate into significant revenue impact. Its acquisition of Hotjar brought self-service session replay and heatmap capability alongside Contentsquare’s enterprise-grade journey analytics, making the combined platform one of the most complete digital experience intelligence offerings available.
Features: zoning analytics measuring engagement across individual content areas on a page, AI-powered CS Ai insight generation on content and journey patterns, heatmaps and scroll maps for visual interaction data, session replay following the Hotjar acquisition, customer journey analysis across multi-step digital flows, frustration signal detection including rage clicks and hesitation, integration with major web analytics and A/B testing tools, e-commerce and conversion funnel analysis, enterprise-scale processing of billions of interactions, and particular strength for large retail, financial services and travel web properties.
Best for: large e-commerce, retail and financial services organizations with high web traffic that need to understand how visitors engage with content at a spatial and visual level, where conversion rate optimization and UX improvements at scale justify an enterprise digital experience analytics investment.
Web, Marketing & Revenue Analytics
These tools track the digital channels and customer relationships that drive revenue, from website traffic and marketing attribution through to customer health, churn risk and sales pipeline intelligence. Their differentiator ranges from privacy-first web analytics as a cookie-free alternative to GA4 to multi-touch attribution across complex paid media mixes to AI-powered pipeline forecasting. Buyers span marketing analysts and web analytics teams through to customer success leaders and revenue operations functions.
Google Analytics 4
Google Analytics 4 is the world’s most widely deployed web analytics platform, adopted by millions of websites and apps and available entirely for free, making it the default starting point for any organization tracking digital traffic. GA4’s event-based data model replaced the session-based model of Universal Analytics, better handling the cross-device, cross-platform customer journeys that characterize modern digital interactions. Its integration with Google Ads enables conversion tracking and audience export directly from the analytics platform, and the BigQuery export makes GA4 data available for custom analysis in the warehouse alongside other data sources. For most small to mid-sized websites, GA4 provides sufficient analytical depth at zero cost, particularly for teams whose primary analytics needs are traffic sources, page engagement and marketing campaign performance. Larger organizations frequently cite GA4’s standard reporting interface as insufficient for complex cross-channel attribution or deep behavioral cohort analysis, and pair it with a dedicated BI platform, a marketing attribution specialist or a product analytics tool for more demanding use cases.
Features: event-based cross-platform and cross-device analytics, seamless Google Ads conversion tracking and audience export, BigQuery native data export for custom warehouse analysis, exploration reports for ad-hoc funnel, path and cohort analysis, predictive audiences using Google’s ML models, free to use at any website traffic scale, real-time reporting, integration with Google Tag Manager, YouTube and Google Search Console, consent mode for privacy-compliant data collection, and adoption by millions of websites globally.
Best for: every organization running a website or app as the baseline web analytics layer, particularly those running Google Ads campaigns where GA4’s native conversion and audience integration provides the tightest feedback loop, and small to mid-sized businesses for whom GA4 provides sufficient depth at no cost.
Adobe Analytics
Adobe Analytics is the enterprise-grade web and digital analytics platform of the Adobe Experience Cloud, providing the analytical depth, segmentation granularity and data fidelity that large organizations running complex multi-channel digital experiences require beyond what GA4 offers. Its Analysis Workspace provides a highly flexible drag-and-drop analytical environment where analysts can build custom attribution models, advanced calculated metrics and multi-dimensional breakdowns that GA4’s standard reporting cannot support. Adobe Analytics processes and stores data with high fidelity, retaining full event-level granularity rather than sampling, which matters for enterprise analytics at high traffic volumes where GA4’s sampling behavior introduces accuracy concerns. Integration with Adobe Target for A/B testing, Adobe Audience Manager for audience activation and other Adobe Experience Cloud products makes it the natural choice for large enterprises already standardized on the Adobe stack. Pricing requires a custom quote and typically represents a significant investment, which positions Adobe Analytics firmly at large enterprise customers rather than mid-market or smaller organizations.
Features: Analysis Workspace drag-and-drop analytical environment with full metric and dimension flexibility, custom attribution modeling across channels, unsampled data processing at enterprise traffic volumes, deep segmentation and audience building, integration with Adobe Target, Audience Manager and Experience Cloud, virtual report suites for multi-brand and multi-region data governance, data feeds for raw data export to warehouses, mobile app analytics SDK, advanced calculated metrics and statistical modeling, and a long track record in enterprise media, retail and financial services analytics.
Best for: large enterprises running complex multi-channel digital experiences that need analysis workspace flexibility, custom attribution models, unsampled data processing and tight integration with Adobe’s broader experience management and targeting stack.
Matomo
Matomo is the leading open-source alternative to Google Analytics, providing comparable web analytics functionality including traffic reports, goal tracking, funnel analysis and e-commerce analytics while storing all data under the organization’s own control rather than on Google’s servers. This data ownership and privacy-first positioning is Matomo’s primary competitive advantage: organizations in regulated industries including healthcare and finance, European companies navigating GDPR data residency requirements, and any organization philosophically opposed to sharing visitor behavior data with a major advertising platform can run Matomo on-premises or on their own cloud infrastructure at no software license cost. Matomo’s cloud-hosted version is available from around $23 per month for small sites, providing managed hosting without the infrastructure responsibility of self-hosting. Feature depth in advanced behavioral analytics is narrower than Amplitude or Mixpanel, and the platform’s analysis capabilities are more comparable to GA4 than to dedicated product analytics tools, reflecting its positioning as a full-fidelity web analytics alternative rather than a product analytics platform.
Features: full-fidelity web analytics with 100 percent data ownership and no third-party data sharing, GDPR and data residency compliant architecture, free open-source self-hosted deployment, cloud-hosted option from around $23 per month, session recordings and heatmaps, funnel analysis and goal tracking, e-commerce analytics, user flow visualization, tag manager, customizable reports, and community and commercial plugin ecosystem extending core functionality.
Best for: organizations that require complete data ownership and cannot share visitor behavior data with Google’s servers, including European businesses with GDPR data residency requirements, regulated industries and privacy-conscious organizations for whom Matomo’s full-fidelity alternative to GA4 justifies the self-hosting operational overhead.
Plausible Analytics
Plausible Analytics is a lightweight, privacy-first web analytics tool built for teams that need clear traffic insights without the complexity of GA4 or the data privacy concerns of sharing visitor data with Google. Its entire analytics script is under one kilobyte, compared with GA4’s substantially heavier tracking, which reduces page load impact and is itself a selling point for performance-conscious publishers. Plausible collects no personal data, uses no cookies and is fully GDPR compliant without requiring cookie consent banners, which is a meaningful operational simplification for sites that would otherwise need to implement and maintain a consent management platform. The dashboard is intentionally simple, covering the core metrics that most publishers, bloggers and small business websites need, including traffic sources, top pages, goals and campaign tracking, without the analytical depth of Matomo, GA4 or a dedicated product analytics tool. Pricing starts from $9 per month for up to 10,000 monthly page views, making it one of the most affordable hosted web analytics options available.
Features: sub-one-kilobyte analytics script with minimal page load impact, cookieless tracking requiring no cookie consent banners, fully GDPR, CCPA and PECR compliant data collection, no personal data collection or cross-site tracking, open-source codebase with a self-hosted option, a clean single-page dashboard covering traffic sources, pages, devices and goals, goal and event tracking, UTM campaign parameter support, pricing from $9 per month, and a strong adoption among privacy-conscious publishers, bloggers and small business websites.
Best for: publishers, bloggers and small business websites that want clear, actionable traffic insights without GDPR cookie consent complexity, heavy page load impact or data privacy concerns about sharing visitor behavior with advertising platforms.
Rockerbox
Rockerbox is a marketing attribution and measurement platform designed for direct-to-consumer and e-commerce brands that need a reliable, multi-touch view of which marketing channels and touchpoints are actually driving customer acquisition across a fragmented paid media landscape. As cookie deprecation, iOS privacy changes and walled-garden attribution limitations have made last-click and native platform attribution less reliable, Rockerbox’s approach of ingesting cross-channel spend and conversion data into a unified view enables brands to compare marketing effectiveness across paid social, search, influencer, podcast, TV and other channels using consistent, methodology-controlled attribution rather than each platform’s self-reported numbers. The platform provides multiple attribution models simultaneously, letting marketing teams see how channel performance changes depending on whether first-touch, last-touch, linear or data-driven attribution is applied, which supports more nuanced channel optimization decisions. Integration with Snowflake and BigQuery allows Rockerbox data to be combined with CRM, email and other datasets for custom analysis beyond what the native dashboard provides.
Features: multi-touch attribution across paid social, search, influencer, podcast and TV channels, resistance to cookie deprecation and iOS privacy changes through server-side and first-party data approaches, multiple attribution model comparison including first-touch, last-touch, linear and data-driven, channel spend and conversion data ingestion into a unified cross-channel view, integration with Snowflake and BigQuery for custom analysis, comparison of actual attributed results versus platform-reported numbers, incrementality testing support, media mix modeling integration, and a DTC and e-commerce brand focus.
Best for: direct-to-consumer and e-commerce brands managing paid media across multiple channels that need reliable multi-touch attribution independent of individual platform self-reporting, particularly those affected by iOS privacy changes and cookie deprecation that have degraded their previous attribution approach.
Northbeam
Northbeam is a media attribution and marketing intelligence platform built specifically for e-commerce and DTC brands, using machine learning attribution models that combine first-party pixel data, server-side tracking and spend ingestion to attribute conversions across channels even when cross-device and cross-browser attribution signals have been degraded by privacy changes. Its real-time ROAS reporting across channels and creative-level attribution, down to individual ad creative performance, gives media buying teams the signal precision needed to optimize campaigns on a daily basis rather than waiting for weekly or monthly attribution reports. Northbeam’s approach to synthetic attribution using statistical modeling helps fill the gaps left by cookie loss and iOS14 signal loss that have rendered simpler last-click attribution unreliable for brands with longer consideration cycles. For high-spend DTC brands with sophisticated media buying operations where accurate attribution directly translates to more efficient media spend decisions, Northbeam’s depth of attribution methodology is its primary differentiator.
Features: ML-powered attribution combining first-party pixel, server-side and spend data, real-time ROAS reporting at channel and creative level, cross-device attribution using synthetic modeling to compensate for signal loss, integration with Meta, Google, TikTok, Pinterest and major paid channels, creative-level performance attribution for media buying optimization, post-purchase survey integration for attribution validation, customer lifetime value modeling, integration with Shopify and major e-commerce platforms, and a high-spend DTC brand focus with sophisticated attribution methodology.
Best for: high-spend DTC e-commerce brands with sophisticated media buying operations that need creative-level attribution accuracy and real-time ROAS visibility across channels, where the precision of Northbeam’s ML-powered attribution methodology translates directly into more efficient paid media spend.
Gainsight
Gainsight is the leading customer success platform, using product usage analytics, health scoring and AI-driven insights to help customer success teams proactively identify accounts at risk of churn, expansion opportunities and onboarding gaps before they become visible in revenue metrics. Its behavioral product analytics layer captures how enterprise customers are using a SaaS product, which features are adopted, which are unused and how usage trends over time, feeding this data into health scores that trigger automated playbooks for customer success managers when an account enters a risk zone. Gainsight has expanded from its original customer success management roots into full product experience management, adding in-app guidance, product analytics and community platform capabilities that extend the platform’s scope across the full customer lifecycle. For B2B SaaS companies managing a book of large enterprise accounts where the cost of undetected churn significantly exceeds the investment in a dedicated customer success platform, Gainsight is frequently the reference standard.
Features: customer health scoring combining product usage, engagement and relationship signals, behavioral product analytics tracking feature adoption and usage depth, AI-powered churn risk identification and expansion opportunity detection, automated customer success playbooks triggered by health score changes, in-app guidance and onboarding tools, NPS and voice of customer collection, a customer community platform, integration with Salesforce, HubSpot and major CRM systems, and the leading market position in B2B SaaS customer success management.
Best for: B2B SaaS companies with a significant book of enterprise accounts and dedicated customer success teams, where proactive churn detection and expansion opportunity identification based on product usage data directly impacts net revenue retention.
Clari
Clari is an AI-powered revenue platform that uses machine learning to analyze CRM data, sales activity signals and pipeline movement to produce more accurate revenue forecasts, identify deals at risk and surface the specific actions most likely to improve close rates, replacing the subjective gut-feel forecasting that characterizes most sales organizations. Its Copilot feature records, transcribes and analyzes sales calls to surface winning behaviors, objection patterns and follow-up commitments, while its platform-wide AI continuously monitors CRM field changes and deal activity to flag which opportunities are progressing and which are stalling. Clari’s company-wide revenue collaboration model extends beyond the sales team to align finance, customer success and marketing on a shared, AI-generated view of revenue performance, replacing the patchwork of disconnected spreadsheets that most organizations use for revenue planning. For revenue organizations that treat forecasting accuracy as a strategic metric and want AI to provide analytical depth that CRM reporting alone cannot deliver, Clari is one of the most widely evaluated revenue intelligence platforms.
Features: AI-powered pipeline forecasting with ML-based deal progression analysis, Copilot sales call recording, transcription and behavior analysis, deal risk identification and recommended next-action suggestions, CRM activity signal monitoring and automated field updates, company-wide revenue collaboration across sales, finance and customer success, real-time pipeline visibility replacing spreadsheet-based forecasting, conversation intelligence with objection and commitment tracking, integration with Salesforce, HubSpot and major CRM platforms, and a revenue operations platform positioning across the full commercial function.
Best for: revenue operations leaders and sales organizations that want AI-powered forecast accuracy and deal risk intelligence beyond what CRM reporting provides, particularly enterprise sales teams managing complex multi-stakeholder deals where pipeline visibility and coaching insights directly affect close rates.
ChurnZero
ChurnZero is a customer success and churn prevention platform specifically sized and priced for mid-market SaaS companies that need the core capabilities of enterprise customer success tooling, including health scoring, automated playbooks and engagement tracking, without the complexity and cost of an enterprise Gainsight deployment. Its real-time customer health scoring combines product usage data, engagement signals and CRM activity into scores that trigger automated outreach, task creation and playbook execution for customer success managers, reducing the manual monitoring burden that makes customer success teams reactive rather than proactive. ChurnZero’s SuccessCenters provide in-app notification and resource delivery for customers, and its NPS collection and analysis tools surface satisfaction signals alongside behavioral data. For mid-market B2B SaaS companies with growing customer success teams that find Gainsight over-engineered or out of budget, ChurnZero is the most frequently recommended alternative.
Features: real-time customer health scoring combining usage, engagement and CRM signals, automated playbooks triggered by health score changes, SuccessCenters for in-app resource and notification delivery, NPS and sentiment tracking alongside behavioral data, task management and customer success manager workflow tools, revenue forecasting and renewal risk identification, integration with Salesforce, HubSpot and major billing systems, onboarding milestone tracking, reporting dashboards for customer success team leadership, and mid-market SaaS pricing accessible below Gainsight’s enterprise tier.
Best for: mid-market B2B SaaS companies with growing customer success teams that want the core capabilities of enterprise customer success tooling, including health scoring and automated playbooks, at pricing and implementation complexity appropriate for their scale.
Data Science, Notebooks & Data Preparation
This category covers the tools used by data scientists, analytics engineers and technically proficient analysts for exploratory analysis, statistical modeling, machine learning experimentation and data wrangling, ranging from the ubiquitous Jupyter notebook environment to collaborative cloud notebooks with built-in data connections to powerful no-code data preparation platforms. Their differentiator spans from open-source flexibility to collaborative SQL and Python environments to drag-and-drop workflow builders that eliminate coding requirements entirely. Buyers are individual data scientists, analytics engineering teams and organizations trying to make advanced analytical workflows accessible to less technical practitioners.
Jupyter
Jupyter is the foundational open-source notebook environment for data science and scientific computing, providing an interactive computing interface where code, visualizations, equations and narrative text coexist in a single shareable document. Running as a local server or in hosted cloud environments including Google Colab, AWS SageMaker and Azure ML, Jupyter supports kernels for Python, R, Julia and dozens of other languages, making it the most language-flexible analytical environment available. JupyterLab, the next-generation interface, extends the classic notebook with a full IDE experience including file browsing, terminal access and multiple notebook tabs. Despite its age, Jupyter remains the default analytical environment for data scientists, machine learning researchers and academic analytics, and virtually every managed data platform, from Databricks to Snowflake to BigQuery, provides a Jupyter-compatible notebook interface. Its main limitations are collaboration, version control and reproducibility: real-time co-editing, clean git integration and consistent execution environments all require additional tooling or managed platforms built on top of the core Jupyter project.
Features: open-source interactive notebooks combining code, visualizations, equations and narrative text, Python, R, Julia and multi-language kernel support, JupyterLab full IDE interface with file browser and terminal, compatibility with virtually every managed data platform and cloud ML environment, free to use with no licensing cost, the most widely used analytical environment in data science and academic research, broad library ecosystem access including pandas, numpy, scikit-learn and matplotlib, integration with version control through nbformat, and a massive community of extensions and tools built on the Jupyter protocol.
Best for: individual data scientists, ML researchers and academic analysts who need a flexible, language-agnostic environment for exploratory analysis, statistical modeling and machine learning experimentation, and for data teams working within managed platforms like Databricks or SageMaker that provide Jupyter-compatible interfaces.
Hex
Hex is a collaborative analytics platform that combines a SQL and Python notebook environment with a no-code app publishing layer, letting analysts build analyses in code and then surface results as interactive, shareable applications that business stakeholders can explore without seeing the underlying code. Its real-time collaborative editing, unlike Jupyter where simultaneous editing causes conflicts, makes it practical for teams of analysts to work on the same notebook simultaneously, and its Magic AI features generate SQL and Python from natural language descriptions, accelerating the development of analytical workflows. Hex connects directly to Snowflake, Databricks, BigQuery, Redshift and dozens of other databases, providing a live data environment without the file-upload workflow of tools like Julius AI. The platform’s Component Store provides reusable, shared SQL and Python components that data teams can build once and reuse across projects, reducing duplicated analytical work. Hex has established itself as one of the strongest purpose-built collaborative notebook platforms for data teams that outgrown Jupyter’s collaboration limitations but do not want to move all analysis into a BI platform.
Features: collaborative real-time SQL and Python notebook environment, Magic AI for natural language SQL and Python code generation, no-code app publishing layer for sharing interactive results with business stakeholders, a Component Store for reusable shared analytical building blocks, direct connections to Snowflake, Databricks, BigQuery, Redshift and major databases, version control and branching for notebook history, scheduled notebook runs for automated analytical workflows, team workspace with permissions and access control, and a purpose-built collaborative environment overcoming Jupyter’s simultaneous-editing limitations.
Best for: data analyst and analytics engineering teams that outgrow Jupyter’s collaboration limitations and want a cloud-native notebook environment where simultaneous editing, code reuse and business-facing app publishing are first-class features rather than afterthoughts.
RStudio / Posit
RStudio / Posit now operating under the Posit brand following a rebrand reflecting the company’s expanded support for Python alongside R, provides the definitive development environment for statisticians and quantitative researchers who use R as their primary analytical language. Posit’s products span RStudio Desktop and Server for interactive R development, Posit Workbench for enterprise multi-user server deployments, Quarto for reproducible research document publishing across R, Python and Julia, and Posit Connect for sharing and scheduling Shiny apps, R Markdown reports and Jupyter notebooks within an organization. The R ecosystem’s statistical computing depth, particularly for econometrics, biostatistics, survey analysis and clinical trial analytics, remains unmatched in many specialized research domains, and RStudio’s integration with the tidyverse, ggplot2 and the broader R package ecosystem provides the most productive development environment for R users. Organizations that rely primarily on Python for data science rather than R will find less value in the Posit environment specifically, though Quarto’s multi-language support reduces the R-only lock-in of earlier Posit products.
Features: RStudio IDE for interactive R and Python development, Posit Workbench for enterprise multi-user server deployments, Quarto reproducible research publishing across R, Python and Julia, Posit Connect for sharing Shiny apps, R Markdown and Jupyter notebooks, deep integration with tidyverse, ggplot2 and the R package ecosystem, Version control through Git integration, enterprise authentication and access control on Workbench and Connect, Shiny for interactive web applications built in R, and the definitive development environment for the global R statistical computing community.
Best for: statisticians, quantitative researchers and data scientists whose primary analytical language is R, particularly in biostatistics, clinical research, econometrics and social science domains where R’s statistical computing ecosystem has depth that Python libraries do not fully replicate.
Alteryx
Alteryx is the dominant no-code to low-code data preparation and analytics workflow platform, providing a drag-and-drop visual canvas with more than 300 native connectors that lets analysts ingest, clean, blend and reshape complex datasets and build repeatable analytical workflows without writing code. Its Designer Desktop application has been the go-to tool for business analysts in financial services, retail and healthcare who need to perform data preparation tasks that would otherwise require SQL or Python expertise, and its machine learning and predictive analytics tools extend the platform from pure data wrangling into statistical modeling through the same drag-and-drop interface. Alteryx Platform, the cloud offering, adds collaboration, scheduling and governance on top of the desktop capabilities, and the company has invested in AI-powered tools that suggest transformations and automate repetitive data preparation steps. For organizations where data preparation bottlenecks analytics delivery and the practitioners doing the work are not SQL-proficient, Alteryx’s workflow automation can represent a significant productivity gain.
Features: drag-and-drop visual workflow canvas with 300-plus native data connectors, no-code data preparation including joining, filtering, pivoting and reshaping, predictive analytics and ML models through the same visual interface, Alteryx Platform for cloud collaboration and scheduled workflow execution, AI-powered transformation suggestions, integration with Snowflake, Databricks, Salesforce and major enterprise systems, a Python and R tool for extending workflows with custom code, spatial analytics and geospatial processing, and strong adoption among business analysts in financial services, retail and healthcare.
Best for: business analyst teams in financial services, retail and healthcare that need to perform complex data preparation and repeatable analytical workflows without SQL or Python proficiency, where Alteryx’s drag-and-drop approach reduces dependence on data engineering for analytical delivery.
Polymer
Polymer is a no-code AI analytics tool designed for the simplest possible entry point into data visualization: upload a spreadsheet or CSV file, and Polymer automatically generates charts, identifies patterns and builds a shareable interactive dashboard in under a minute, with no configuration, SQL or analytical training required. Its AI engine highlights trends, outliers and seasonal patterns in the data automatically, providing surface-level insights that would be visible to a skilled analyst but that non-technical business users typically need help identifying. Polymer’s strengths are speed and accessibility: getting from a raw spreadsheet to a shareable visualization is faster with Polymer than with any other tool in this guide. Its limitations are equally pronounced: the platform has no formula engine, no statistical testing, no multi-dataset joining and no support for database connections beyond file uploads, making it unsuitable for anything beyond quick pattern detection and stakeholder-facing presentation of pre-prepared data. Polymer is best understood as the analytical equivalent of a presentation tool: excellent at making data look clear and accessible quickly, but not designed for the kind of investigation that precedes an insight.
Features: automatic chart and dashboard generation from uploaded CSV or spreadsheet files, AI-powered pattern, trend and outlier highlighting, a shareable interactive dashboard produced in under one minute from file upload, no SQL, code or analytical training required, filter and drill-down functionality for stakeholder exploration, no infrastructure or account setup required for basic use, accessible pricing with free and paid tiers, and the fastest time from raw data file to shareable visualization of any tool in this guide.
Best for: non-technical business users and small teams that need to turn a pre-prepared spreadsheet into a shareable visualization quickly for a presentation or stakeholder update, where speed and accessibility matter more than analytical depth.
Microsoft Excel
Microsoft Excel remains the most widely used data analysis surface in the world across every industry and organization size, with its grid-based calculation model, PivotTable aggregation engine and chart library constituting the default analytical environment for the vast majority of business users who will never open a BI platform. This guide would be incomplete without acknowledging it: more data analysis is performed in Excel every day than in every other tool in this article combined, and its role as the entry point through which most business users first engage with data makes it foundational context for every tool above it on this list. Microsoft 365 Copilot brings generative AI into Excel, allowing users to analyze data, create PivotTables and generate insights through natural language prompts, and the Power Query data connection and transformation layer allows Excel to pull live data from databases and cloud sources rather than working only with static files. Excel’s limitations as an analytics platform, including no version control, collaboration friction, row limits for very large datasets and no semantic layer, are well-documented, but for the overwhelming majority of business analytical tasks, it remains the most immediately accessible tool available.
Features: PivotTable and PivotChart aggregation and visualization, Microsoft 365 Copilot natural language analysis and insight generation, Power Query for live data connections to databases and cloud sources, a formula library covering statistical, financial and text functions, conditional formatting and data validation, Power Pivot for in-memory data modeling beyond worksheet row limits, integration with Power BI for publishing to governed dashboards, native integration with Teams, SharePoint and Microsoft 365, and availability on desktop, mobile and web with offline capability.
Best for: every business user performing day-to-day data analysis, financial modeling, reporting and planning, and as the universal baseline analytical surface that contextualizes the value proposition of every more specialized tool in this guide.
Embedded & Open-Source Analytics
This final category covers tools for embedding analytics directly into customer-facing products, and the open-source alternatives that provide capable analytics infrastructure at zero license cost. Their differentiator is either the depth of developer-first APIs for building analytics-as-a-product, or the elimination of licensing cost for teams comfortable managing open-source infrastructure. Buyers are product engineers building analytics features into SaaS products, and engineering-led organizations optimizing data infrastructure spend.
GoodData
GoodData is an API-first embedded analytics platform designed for SaaS companies and software vendors that need to deliver analytics capabilities to their own end users at scale, with fine-grained multi-tenant data isolation ensuring that each customer sees only their own data in a shared infrastructure. Its headless BI architecture separates the analytical computation and metric governance layer from the user interface layer, giving development teams the flexibility to build custom analytics experiences using GoodData’s React SDK and REST APIs rather than being constrained by a vendor-defined dashboard template. This API-first design is GoodData’s primary differentiator relative to Sisense: it assumes engineering-led implementation and rewards teams that want to build deeply customized analytics experiences, while Sisense’s more complete out-of-box dashboard layer suits teams that want to embed with less custom development. GoodData’s semantic layer manages metric definitions centrally across all embedded instances, ensuring that a customer’s revenue metric means the same thing in every dashboard their end users see regardless of which tenant is viewing it.
Features: API-first headless BI architecture for custom analytics experiences, multi-tenant data isolation for SaaS customer-facing deployment, React SDK and REST APIs for developer-driven customization, centralized semantic layer for consistent metric definitions across tenants, white-labeling and full UI customization, scalable to thousands of end-user tenants, integration with Snowflake, Databricks, BigQuery and Redshift, fine-grained access control per tenant, a workspace management API for automated tenant provisioning, and strong adoption among SaaS ISVs building analytics-as-a-product.
Best for: SaaS companies and software vendors building analytics directly into their products for thousands of end-user tenants, that want API-first, developer-controlled customization rather than a vendor-defined dashboard template, and that need robust multi-tenant data isolation guaranteeing each customer sees only their own data.
Redash
Redash is an open-source data querying and dashboard tool originally built at Fiverr and designed to let anyone in an organization write SQL queries against connected data sources and turn the results into shareable dashboards without needing a full BI platform. Its simplicity is both its strength and its limitation: connecting a database, writing a query and sharing the result as a dashboard takes minutes, and the platform’s architecture is straightforward enough that a single engineer can deploy and maintain it. Redash supports a wide range of data sources through query runners, connecting to SQL databases, cloud warehouses, API endpoints and NoSQL stores with a consistent SQL-like interface. Compared with Metabase, its closest open-source competitor, Redash is more query-editor-first and less optimized for non-technical business users who want to explore data without writing SQL. The open-source project was acquired by Databricks in 2020, though Redash continues to operate as an independent open-source project with community maintenance.
Features: open-source SQL query editor and dashboard builder with no licensing cost, wide data source support including SQL databases, cloud warehouses and API endpoints, shareable query results as interactive dashboards, scheduled query execution and automated report delivery, a simple, query-editor-first interface for SQL-comfortable analysts, alerting on query result changes, a fork and extend model for custom development, community-maintained open-source project with an active GitHub repository, and fast deployment for engineering teams comfortable with self-hosted infrastructure.
Best for: engineering-led organizations and technical data teams that want a simple, SQL-first open-source dashboard tool for internal reporting, where the primary users are analysts comfortable writing queries and the platform’s simplicity and zero license cost outweigh the need for business-user-friendly self-service features.
Grafana
Grafana is the leading open-source observability and operational analytics platform, originally built for time-series and infrastructure monitoring but now supporting a wide range of data sources through a plugin ecosystem covering databases, cloud services and APIs. For data teams running analytics on operational metrics, real-time event streams or infrastructure performance data alongside their BI analytics, Grafana fills a distinct gap that traditional BI platforms were not designed to address: sub-second refresh on streaming metrics, visualization of time-series data with alerting on threshold breaches and operational dashboard patterns built for engineering and operations teams rather than business analysts. Grafana Cloud provides a managed hosting option for teams that want to avoid infrastructure management, and the enterprise offering adds enhanced security, governance and support for larger deployments. Its data source plugin ecosystem means Grafana can query virtually any system without requiring data to be extracted to a central warehouse first, which matters for operational use cases where latency between event occurrence and dashboard visibility must be minimized.
Features: open-source time-series and operational analytics with a massive plugin ecosystem, sub-second refresh for real-time streaming metric dashboards, alerting and notification on threshold and anomaly conditions, multi-source dashboard composition querying different data systems simultaneously, Grafana Cloud managed hosting with a generous free tier, Grafana Enterprise with enhanced security and governance, integration with Prometheus, InfluxDB, Elasticsearch, Snowflake, BigQuery and hundreds of other sources, Loki for log analytics and Tempo for distributed tracing alongside metrics, and the default operational analytics platform in the modern DevOps and SRE stack.
Best for: engineering, DevOps and SRE teams that need real-time operational dashboards and alerting on infrastructure metrics, application performance and event streams, where Grafana’s time-series optimization and plugin breadth serve operational analytics needs that traditional BI platforms were not designed to address.
Comparison Table: 59 Best Data Analytics Tools
The table below maps all 59 reviewed tools by category, summarising the primary strength, the buyer profile and indicative pricing for each. The majority of enterprise and specialist tools are custom-quoted; where a published starting price or pricing model exists it is noted. Pricing data reflects publicly available information as of mid-2026 and should be verified directly with vendors before procurement decisions.
| Tool | Primary Strength | Best Fit | Pricing |
| Enterprise BI & Dashboards | |||
| Microsoft Power BI | Microsoft 365 ecosystem integration + Copilot AI | Microsoft-standardized orgs, cost-sensitive deployments | $14/user/mo (Pro); Fabric capacity for AI |
| Tableau | Visual depth + agentic Tableau Next + Tableau Pulse | Analytics teams prioritizing visualization quality | $15–$115/user/mo |
| Looker | LookML semantic governance, Google Cloud native | Data-engineering-led orgs, Google Cloud / BigQuery | ~$36,000/yr minimum, custom quote |
| Qlik Sense | Associative engine + Qlik Answers for unstructured data | Complex multi-source exploration, regulated industries | From ~$200/mo for 10 users |
| Domo | All-in-one: ingestion + ETL + BI + AI in one platform | Mid-market minimizing multi-vendor stack complexity | ~$134,000/yr avg enterprise |
| Sisense | Developer-first embedded analytics for SaaS products | SaaS companies embedding analytics in their product | From ~$10,000/yr |
| Metabase | Fastest time-to-value, free open-source option | Startups and SMBs wanting low-cost accessible BI | Free (OSS); Cloud from ~$500/mo |
| Google Looker Studio | Free + native Google Ads / GA4 / BigQuery integration | Marketing teams on Google ecosystem, zero budget | Free; Pro ~$9/user/mo |
| Zoho Analytics | SMB-friendly pricing + Zoho suite integration | SMBs on Zoho suite, budget-conscious teams | Free tier; paid from ~$30/mo |
| Amazon QuickSight | Session-based pricing for large occasional-user bases | AWS-native orgs with many infrequent dashboard viewers | $0.30/reader session; flat-rate option |
| Apache Superset | Zero-license open-source SQL + visualization | Technical teams wanting free, database-agnostic BI | Free (OSS); Preset managed from $20/mo |
| Mode Analytics | Unified SQL + Python notebook + dashboard for analysts | Data analyst teams doing SQL-first exploration | Custom quote (ThoughtSpot company) |
| AI-Native & Augmented Analytics | |||
| ThoughtSpot | Search-based NLQ + SpotIQ auto-insights on warehouse | Enterprises enabling business-user self-service at scale | $25–$50/user/mo; enterprise custom |
| Sigma Computing | Spreadsheet UI + live warehouse + Sigma Agents | Business analysts on Snowflake / Databricks | Custom quote |
| Microsoft Fabric | Unified data + AI platform, Copilot across all workloads | Microsoft-standardized orgs rebuilding data platform | Included in M365 E5; capacity pricing |
| Tellius | Automated root-cause analysis explaining why metrics changed | Enterprise pharma, CPG, financial services analytics | Custom, subscription-based |
| DataGPT | Multi-step analyst-level root-cause investigations | Data-forward orgs wanting AI-driven investigation depth | Custom quote |
| Julius AI | Instant conversational file-upload analysis for individuals | Individual analysts, students, quick one-off exploration | $20–$45/month |
| Cloud Data Warehouses & Lakehouse Platforms | |||
| Snowflake | Broadest BI ecosystem integration + Cortex AI | Multi-tool modern data stacks, neutral warehouse | Consumption-based compute credits |
| Databricks | Unified data engineering + ML + SQL analytics | ML-heavy teams combining data science and analytics | Consumption-based DBUs |
| Google BigQuery | Serverless auto-scaling + Gemini AI + Looker native | Google Cloud / Looker / GA4 ecosystem | Per-query or flat-rate editions |
| Amazon Redshift | Deep AWS ecosystem integration | AWS-native orgs with existing Redshift investments | On-demand or reserved instance pricing |
| ClickHouse | Sub-second queries on billions of rows, real-time ingestion | Event-driven, time-series and operational analytics | Free (OSS); Cloud consumption-based |
| Data Integration, Transformation & Orchestration | |||
| Fivetran | 500+ managed connectors, zero maintenance, reliability | Teams prioritizing connector reliability over cost | Consumption-based Monthly Active Rows |
| dbt Labs | SQL transformation with software engineering practices | Analytics engineers standardizing transformation | Free (Core OSS); dbt Cloud from $100/mo |
| Airbyte | 350+ OSS connectors, free self-hosted option | Cost-constrained teams, custom connector needs | Free (self-hosted); Cloud from $0 |
| Apache Airflow | Broadest orchestration operator ecosystem | Complex multi-step pipeline scheduling and monitoring | Free (OSS); Astronomer managed cloud |
| Matillion | Visual low-code ELT for mixed technical teams | Mid-enterprise teams including non-engineer practitioners | Custom quote |
| Qlik Talend | Enterprise ETL + data quality + master data management | Enterprises with legacy systems and MDM requirements | Custom enterprise quote |
| Data Governance, Cataloging & Observability | |||
| Atlan | Modern-stack catalog + active metadata + AI governance | Modern data stack teams wanting fast deployment | Custom, tiered by connectors |
| Collibra | Formal policy stewardship for regulated industries | Financial services, healthcare, government compliance | From ~$122,600/yr (Standard, 20 creators) |
| Alation | Analyst-friendly catalog + high user adoption | Analytics-first orgs without regulatory governance needs | ~$80,000–$300,000+/yr custom |
| Monte Carlo | ML-powered data observability, automated incident detection | Data engineering teams managing production pipeline risk | Custom, consumption-based |
| Microsoft Purview | Azure-native governance across the Microsoft data estate | Microsoft Azure / Fabric-standardized organizations | ~$0.50/governed asset/day |
| Product & Digital Experience Analytics | |||
| Amplitude | Broadest product analytics + AI + built-in experimentation | Scaling companies needing platform depth and AI | Free Starter; Growth custom; Enterprise custom |
| Mixpanel | User-centric analytics, faster setup, event-based pricing | B2B SaaS with many users, moderate event volume | Free tier; Growth from ~$20/mo |
| PostHog | Open-source, self-hosted, full product analytics stack | Privacy-sensitive, engineering-led, cost-constrained teams | Free (1M events/mo); usage-based cloud |
| Heap | Autocapture with no pre-defined event instrumentation | Teams shipping fast needing retroactive behavior analysis | Free tier; Enterprise custom |
| Pendo | Analytics + in-app guidance + NPS in one platform | Teams closing the loop from insight to in-app action | Custom, per-MAU pricing |
| Fullstory | Session replay + DX Data behavioral search depth | UX research, engineering debugging of specific flows | Enterprise custom |
| Contentsquare | Zone-level content engagement + AI insights + Hotjar | Large e-commerce and retail digital experience teams | Enterprise custom |
| Web, Marketing & Revenue Analytics | |||
| Google Analytics 4 | Free web analytics + Google Ads native integration | Every organization with a website or app | Free |
| Adobe Analytics | Enterprise web analytics + Analysis Workspace depth | Large enterprises on Adobe Experience Cloud | Custom enterprise quote |
| Matomo | GDPR-compliant 100% data ownership GA4 alternative | European orgs, regulated industries, privacy-conscious | Free (self-hosted); Cloud from ~$23/mo |
| Plausible Analytics | Cookieless, sub-1KB, GDPR-compliant web analytics | Publishers, bloggers, small business websites | From $9/month |
| Rockerbox | Multi-touch attribution across paid channels | DTC brands navigating iOS/cookie attribution loss | Custom quote |
| Northbeam | ML attribution + real-time ROAS + creative-level data | High-spend DTC brands with sophisticated media buying | Custom quote |
| Gainsight | Customer health scoring + AI churn and expansion detection | Enterprise B2B SaaS customer success teams | Custom enterprise quote |
| Clari | AI pipeline forecasting + revenue intelligence | Revenue operations and enterprise sales organizations | Custom enterprise quote |
| ChurnZero | Health scoring + playbooks sized for mid-market SaaS | Mid-market B2B SaaS customer success teams | Custom, mid-market pricing |
| Data Science, Notebooks & Data Preparation | |||
| Jupyter / JupyterLab | Universal data science notebook environment | Data scientists, ML researchers, academic analytics | Free (open-source) |
| Hex | Collaborative SQL + Python notebooks + app publishing | Analyst teams outgrowing Jupyter collaboration limits | Free tier; Teams from $24/mo |
| RStudio / Posit | Definitive R development environment | Statisticians and quantitative researchers using R | Free (Desktop); Workbench enterprise custom |
| Alteryx | No-code drag-and-drop data prep + analytics workflows | Business analysts without SQL / Python proficiency | Custom enterprise quote |
| Polymer | Instant AI dashboard from uploaded spreadsheet | Non-technical users needing fast shareable visualization | Free tier; paid from ~$20/mo |
| Microsoft Excel | Universal baseline analytics surface | Every business user performing day-to-day data analysis | Included in Microsoft 365 from $6/mo |
| Embedded & Open-Source Analytics | |||
| GoodData | API-first headless BI for multi-tenant SaaS embedding | SaaS ISVs building analytics-as-a-product at scale | Custom, consumption-based |
| Redash | Simple open-source SQL query + dashboard tool | Technical teams wanting free SQL-first dashboards | Free (OSS) |
| Grafana | Open-source time-series and operational monitoring | DevOps, SRE and engineering ops analytics teams | Free (OSS); Cloud free tier; Enterprise custom |
How to Select Data Analytics Tools for Your Organization
With 59 tools across nine categories, the selection challenge is not finding capable software but correctly identifying which categories of the analytics stack your organization actually needs to invest in right now versus which can be deferred, approximated with a simpler tool or solved with something already in your existing vendor portfolio. The five frameworks below are designed to help you sequence those decisions.
1. Distinguish infrastructure from analytics, and sequence them correctly
The most common and costly mistake in analytics investment is purchasing a sophisticated BI or AI analytics platform before the underlying data infrastructure is ready to support it. A ThoughtSpot or Tellius deployment that sits on inconsistently modeled, poorly governed data will produce unreliable AI-generated insights that erode trust faster than a simple dashboard ever would. Before investing heavily in the analytics layer, organizations should have answers to three infrastructure questions: Where does data live, and can it be queried at reasonable speed? Who is responsible for transforming raw data into clean, well-documented analytical models? And who can a business user trust when a number in a dashboard looks wrong? If those questions have no clear answers, the highest-return investment is typically in warehouse, transformation tooling and governance before BI, not the reverse. The modern data stack ordering, ingest first, transform second, govern third, then analyze, exists for practical reasons that organizations that skip steps learn the hard way.
2. Match the tool to the analytical question, not the category name
Web analytics, product analytics, BI and marketing analytics are different tools solving different questions, and selecting the wrong category for a given question is a common source of analytical frustration. Google Analytics 4 answers where traffic comes from and how pages perform; it was not designed to answer which feature cohort has the highest 90-day retention, which requires a product analytics tool like Amplitude or Mixpanel. A BI platform like Tableau or Power BI answers how business metrics have trended over time; it was not designed to answer why a metric changed at a granular level, which is where Tellius or DataGPT provide something qualitatively different. And a data science notebook like Jupyter or Hex answers whether a statistical relationship exists and what a predictive model suggests; it was not designed to produce the kind of self-service governed dashboard a business analyst needs to check weekly. Clarity about the specific analytical question being asked, not the general category label, is the most reliable selection criterion.
3. Quantify the cost of the problem before the cost of the solution
Enterprise BI platforms, data observability tools and customer success platforms each represent significant investments that are easiest to justify when the cost of the problem they solve is visible in business terms. Data downtime, meaning dashboards surfacing incorrect numbers because of upstream pipeline failures, typically costs organizations in lost analyst time, eroded executive trust in data and delayed decisions; Monte Carlo is most easily justified when that cost is measurable. Forecast inaccuracy in a sales organization costs in missed targets, misallocated resources and surprises at quarter end; Clari is easiest to justify when the existing forecasting error rate has been quantified. Undetected customer churn costs in net revenue retention; Gainsight or ChurnZero are easiest to justify when a cohort analysis has established what a one-percentage-point improvement in retention is worth in annual recurring revenue terms. Vendors will provide ROI calculators but the most credible justification comes from an organization that has done its own baseline measurement before the purchasing conversation begins.
4. Treat the semantic layer as organizational infrastructure, not a vendor feature
One of the most underappreciated decisions in analytics stack design is where metric definitions are stored and governed. In most organizations, the definition of revenue, churn, active user or conversion rate exists in many slightly different versions, one per dashboard, one per team, one per analyst, producing the chronic disagreement over numbers that consumes enormous analytical energy. The modern data stack has produced several partial solutions: dbt’s Semantic Layer centralizes metric definitions for SQL-based transformation, Looker’s LookML enforces definitions through the BI platform, and the Open Semantic Interchange standard launched in 2026 aims to share definitions across platforms. Before selecting a BI or analytics platform, it is worth deciding explicitly where metric definitions will be owned, by the transformation layer in dbt, by the BI platform, or by a standalone semantic layer tool, since this decision shapes which BI tools are compatible, how AI agents will read governed metrics and how metric consistency will be maintained as the organization scales.
5. Run a genuine pilot, not a vendor demo, before committing
The most common failure mode in analytics tool selection is evaluating a platform against the vendor’s curated demo dataset rather than the organization’s own data and actual analytical questions. A tool that handles a well-structured retail dataset elegantly in a sales presentation may struggle with the specific data quality issues, business logic complexity or volume characteristics of a particular organization’s actual warehouse. The most informative pilot takes a real analytical question that matters to a business stakeholder, connects it to actual production data rather than a sanitized sample, and measures whether the platform produces a reliable, trustworthy answer at acceptable speed. For AI analytics platforms specifically, the pilot should include questions where the expected answer is already known from prior manual analysis, to verify that the AI’s output matches reality rather than producing a plausible-sounding but incorrect insight. Time to first reliable, trusted answer on a real question is the metric that predicts long-term adoption better than any feature comparison.
The defining characteristic of a well-designed data analytics stack in 2026 is not any single platform but the combination of infrastructure reliability, metric governance and tool-to-question alignment that lets every person in the organization, from a data scientist building a predictive model to a marketer checking campaign performance to an executive reviewing quarterly results, get to a trusted answer in the time it actually takes them to think of the question. Whether that means a warehouse-native Sigma workbook sitting on a Snowflake semantic layer for a business analyst, a Tellius root-cause investigation for a product leader trying to explain why a KPI dropped, or a PostHog self-hosted deployment for a privacy-conscious engineering team, the right answer is the one that produces a decision faster and more reliably than the previous approach. In an environment where AI is lowering the barrier to sophisticated analysis on one hand and raising the stakes for data quality and governance on the other, the organizations that invest as thoughtfully in the reliability of their data foundation as in the sophistication of their analytical interface are the ones that will close the gap between having data and making better decisions with it.
Keep up to date with our stories on LinkedIn, Twitter, Facebook and Instagram.
